Résumé
Les manuscrits médiévaux sont des objets complexes et fragiles. Afin de les préserver, une campagne de numérisation est en cours, mais, au-delà de la conservation, d’autres perspectives de recherche s’ouvrent à nous. Grâce aux outils numériques il est possible d’extraire des données des images numériques de manuscrits médiévaux de façon partiellement automatique. Le but du projet « Formes et couleurs des manuscrits médiévaux » était de réunir pour la première fois médiévistes et informaticiens autour de ces manuscrits, afin de poser les bases d’une collaboration durable et mutuellement enrichissante.
Abstract
Middle-Aged manuscripts are complex and delicate items. A digitisation campaign is in currently progress in order to save them, but there are other applications to digitisation. Thanks to half-automated digital techniques many data can be extracted from these digital images. The goal of the project “Shapes and colours of the medieval manuscripts” was to unite middle-ages humanists and computer scientists for the first time in order to build a lasting partnership that is mutually rewarding.
Sommaire
- Introduction au projet
- Cadre de l’étude
- Nos premiers résultats
- Conclusion et perspectives
- Bibliographie
Introduction au projet
Parmi les différents types de documents patrimoniaux, les manuscrits anciens sont probablement ceux dont la numérisation est la plus impérative. En effet, ces derniers sont fragilisés par le temps et, lorsqu’ils ne se désagrègent pas naturellement, souffrent d’être trop souvent manipulés pour consultation.
Pour pallier ce danger, une politique de microfilmage systématique des manuscrits anciens a été mise en place depuis 1979 par l’IRHT avec l’appui de l’État. Malheureusement, les microfilms eux-mêmes vieillissent et la qualité des prises de vues varie selon le matériel utilisé et la date du microfilmage.
Aujourd’hui, il est devenu plus avantageux de numériser plutôt que microfilmer les manuscrits non encore traités. De plus, les microfilms issus de la campagne de l’IRHT sont numérisés en grande quantité par ce dernier ou par les bibliothèques qui conservent les manuscrits originaux.
Or de nombreuses questions se posent et s’imposent à nous face à la numérisation en masse des milliers de manuscrits médiévaux conservés dans l’ensemble des bibliothèques publiques [Smith 2001]. Ces questions, d’ordre scientifique, technique ou même juridique, n’ont pas encore toutes trouvé de réponse. Voici une liste non exhaustive des questions qui ont été soulevées à la création du projet « Formes et couleurs des manuscrits médiévaux » :
- Comment garantir la conservation pérenne des données obtenues ?
- Comment décrire et trier utilement les textes, les écritures, les images engrangées, notamment en développant pour ces dernières une reconnaissance automatisée des formes et des couleurs ?
- Quelles conditions juridiques faut-il prévoir pour mettre en ligne ces données numériques, et ainsi pour les mettre à la disposition des chercheurs ou d’un public plus large, tout en respectant les droits des institutions conservant les manuscrits ?
- Quels changements ce saut du manuscrit au numérique, en quelque sorte « par-dessus » l’imprimé, va-t-il entraîner sur les pratiques scientifiques de l’historien ? Quelle répercussion aura-t-il sur l’accès de l’ensemble des utilisateurs à ces sources premières – textes, images, musique – de l’histoire ancienne et médiévale ?
Le corpus des manuscrits du Moyen Âge est certes de grande taille (environ 25 000 manuscrits dans les fonds traités par l’IRHT, soit 6,250 millions de folios ou vues de microfilms, soit près de 18 km de films), mais il présente l’avantage d’être fixé ; sauf un tout petit nombre d’acquisitions, aucun manuscrit nouveau n’y sera ajouté.
Ce corpus nous permet d’étudier un phénomène nouveau. En effet, le manuscrit a été remplacé par le livre imprimé, ce qui induit un grand nombre de modifications dans la définition de l’objet « livre ». Le livre imprimé est aujourd’hui en passe d’être supplanté par le document électronique avec la myriade de nouveautés et de changements qui l’accompagnent. Nous avons aujourd’hui l’occasion d’étudier le passage direct du manuscrit au document électronique et l’ensemble des modifications observables entre ces deux étapes n’est pas nécessairement la somme des nouveautés apparues entre le manuscrit et l’imprimé puis entre l’imprimé et le numérique. Certaines analogies entre le manuscrit et le document numérique peuvent ainsi être notées :
- difficulté à définir la date de publication : l’œuvre connaît au contraire une diffusion continue et en grande partie incontrôlable ;
- malléabilité du texte et disparition de sa fixité littéraire et intellectuelle ;
- forte importance de l’intertextualité et de l’intratextualité : toute œuvre de la culture manuscrite est constamment référée de mille et une façons à d’autres œuvres antérieures, voire du même auteur, de la traduction à l’apocryphe en passant par le commentaire, la glose, le centon, le florilège, la continuation, l’interpolation et l’adaptation...
- faiblesse de la notion d’auteur et difficulté pour identifier, dater, localiser les œuvres ;
- découplement du livre en une unité intellectuelle, qui a son histoire, et un support matériel, parfois réutilisé pour transmettre d’autres œuvres (palimpsestes) ;
- inventivité et souplesse des possibilités de la mise en page ; par sa structure et ses apparats, parfois à plusieurs niveaux, la Glose ordinaire utilise par exemple des pratiques d’écriture et de lecture qui annoncent l’hypertexte.
In fine, les manuscrits médiévaux, tout comme certains documents électroniques sont des œuvres instables, en perpétuelle évolution et dont la création et la diffusion sont intimement liées.
L’objectif du projet était de réunir pour la première fois médiévistes et informaticiens autour des manuscrits afin de concourir à la définition d’un outil de recherche facilitant l’accès aux bases de données d’images numériques de très grande envergure. En se fondant sur les possibilités technologiques en émergence, le but était d’accroître les possibilités documentaires par la reconnaissance automatisée des formes et des couleurs appliquée aux données mises en ligne. On attendait de l’entreprise que les résultats obtenus ouvrent des horizons extrêmement intéressants permettant de mettre en relation des objets jusqu’alors isolés.
Le projet fut le cadre de discussions et d’échanges entre experts de domaines divers qui ont réfléchi ensemble sur de nouvelles méthodes. Dans le contexte informatique, les bases de tout traitement ont dû être entièrement repensées pour les adapter aux nouveaux documents qui nous furent présentés. Dans un premier temps, les informaticiens jouèrent donc le rôle de demandeur afin d’acquérir les connaissances nécessaires à la mise à jour de leurs boîtes à outils. Ensuite, les rôles furent inversés et, au fil des demandes et des besoins des autres partenaires, des ébauches de solutions ont pu être mises en œuvre, confirmant ainsi la vraisemblance de ce projet singulier.
Dans les faits, le projet aura permis de réaliser de nombreux travaux prospectifs et applicatifs. Une exploration « en largeur d’abord » des possibilités offertes par les outils numériques a été effectuée et de nombreuses pistes ont été découvertes. La durée du projet n’a pas été suffisante pour concrétiser chacune de ces dernières. Cependant, nous avons pu valider ou infirmer nombre d’idées et perspectives, acquérant ainsi une plus grande visibilité, propice à la continuation de tout travail dans le prolongement de ce projet.
Cadre de l’étude
Les manuscrits du Moyen Âge
Fabrication
Au Moyen Âge, la diffusion des documents, nécessairement manuscrits, était très limitée. Chaque manuscrit faisait l’objet de copies en nombre variable, le plus fidèles possible d’ordinaire, mais le procédé impliquait inévitablement des erreurs et oublis.
Jusqu’au xiie siècle, la rédaction des manuscrits était le plus souvent assurée par des moines car les autorités religieuses avaient alors la charge de conserver et transmettre le savoir. Installés dans le scriptorium, une des rares pièces du monastère à être chauffée, les apprentis effectuaient les tâches les plus simples (comme la réglure) et les copistes recopiaient et enluminaient les manuscrits. L’armarius gérait l’armoire, c’est-à-dire la bibliothèque. Lorsque le monastère possédait un scriptorium, l’armarius supervisait et contrôlait aussi le travail des copistes. À partir du xiiie siècle, les écoles cathédrales, sous la direction des évêques, commencent peu à peu à se transformer et deviennent les universités. Dès lors et jusqu’à la fin du Moyen Âge, des instituts laïcs de copie voient aussi le jour.
Avant rédaction, on traçait sur chaque page la réglure : de fines et discrètes lignes droites décrivant la structure de la page (lignes de texte, cadre des enluminures, etc.). Un copiste pouvait ensuite recopier le texte dans les emplacements prévus, s’assurant ainsi de la régularité du texte écrit, tant pour la hauteur des lettres que pour l’horizontalité des lignes de texte. Afin de faciliter l’opération de reliure, le premier mot d’une page était parfois répété en bas de la page précédente (la réclame). En cas d’oubli d’une partie du texte par le copiste, des renvois à la marge pouvaient être effectués à l’aide d’appels de note, ou bien le texte pouvait être ajouté entre deux lignes.
Ensuite, les manuscrits les plus importants étaient transmis à un enlumineur qui ajoutait les lettrines et miniatures. Celles-ci, souvent en couleur, étaient réalisées par des spécialistes. Ces derniers furent d’ailleurs mis à contribution lors de l’édition des premiers livres imprimés.
Description
Chaque manuscrit médiéval est donc unique à deux titres. D’une part, toutes les copies d’un même livre sont différentes car produites par un copiste qui peut commettre des erreurs, puisqu’il est impossible de transcrire sans bévue un texte d’une certaine étendue, de dessiner deux enluminures parfaitement identiques, etc. D’autre part, chaque œuvre est unique car présentée de façon originale : le concept de feuille de style tel que nous l’utilisons aujourd’hui étant alors inconnu, la mise en page d’un même texte varie d’un témoin à l’autre. Décrire très précisément l’ensemble des manuscrits est donc une tâche gigantesque ; aussi donnerons-nous ici une liste des éléments qui peuvent se rencontrer dans lesdits ouvrages.
Le corps du texte principal est disposé sur une ou deux colonnes, parfois davantage. Le texte est d’ordinaire justifié à gauche et à droite, les mots étant césurés si nécessaire. Pour des raisons d’économie de l’espace sur la page, il n’y a généralement pas d’alinéa ni de saut de ligne entre deux paragraphes, mais un titre en couleur, rubriqué (souvent rouge) ou bien un signe appelé « pied de mouche » : Γ ou ¶. Souvent, les réglures se voient encore sur le manuscrit.
Les textes qui faisaient l’objet d’un enseignement sont souvent entourés de « gloses », c’est-à-dire de notes explicatives, tracées alors par les étudiants ou les maîtres eux-mêmes. Lorsque cette annotation est prévue, on espace les lignes du texte principal et on augmente les marges larges pour laisser la place aux gloses. Certaines gloses particulièrement réputées sont ensuite recopiées en même temps que le texte par les copistes, on les appelle alors gloses ordinaires.
L’enluminure se compose d’illustrations figuratives (par exemple les miniatures) ou décoratives (par exemple certaines lettrines) ornant le document. Ces dernières peuvent être insérées dans le texte ou en sortir pour descendre le long des colonnes, parfois jusqu’à les encadrer. La richesse de l’ornementation des lettrines et leur taille sont souvent modulées de manière à souligner l’organisation hiérarchique du texte.
En dehors des marges, on évitait d’ordinaire d’aérer le manuscrit par des espaces blancs. Le texte commençait en haut à gauche de la première page et ce n’est qu’à la fin du livre que sont donnés dans un colophon le titre, le nom de l’auteur, la date, le nom du copiste, etc.
Dans leur grande majorité, les manuscrits médiévaux ne sont pas paginés mais foliotés, c’est-à-dire qu’on numérote feuillet par feuillet (avec donc un recto et un verso). On trouve quelques foliotations médiévales en chiffres romains ou arabes, mais le plus souvent c’est au xixe ou au xxe siècle que la foliotation a été réalisée par le bibliothécaire. Les numéros de folios sont alors portés en haut à droite de chaque recto de feuillet, dans une écriture récente.

Caractère spécifique
Bien que manuscrits, les documents du Moyen Âge sont très dissemblables des manuscrits modernes et contemporains. En effet, ces derniers ne sont soumis à aucune règle de mise en page. Certains brouillons d’auteurs contiennent du texte dans différentes directions et sur plusieurs couches alors que les manuscrits médiévaux sont, à l’intérieur d’un même volume, formatés de manière plus ou moins stricte : une réglure est tracée avant la rédaction et la plupart du temps les notes sont ajoutées proprement dans une marge. En cela, les manuscrits médiévaux semblent plus aisés à analyser.
Il est alors intuitif de vouloir comparer les manuscrits médiévaux aux livres imprimés, d’autant plus que la plupart d’entre eux ne sont pas cursifs. L’apparente organisation desdits manuscrits est pourtant porteuse de grandes difficultés car la mise en page ne suivait généralement pas une « feuille de style » comme les documents que nous rédigeons quotidiennement de nos jours. De plus, les enluminures et autres ajouts (gloses, etc.) viennent parfois s’ajouter en surimpression et rendent alors très sophistiqué l’agencement des différents objets sur la page. Pour des raisons d’économie, les grandes divisions du texte (livres, chapitres) dans un même volume sont rarement séparés par des blancs. Seuls quelques mots-clés ou phrases de transition les séparent, alors qu’un saut de page, ou au minimum de ligne, est de rigueur dans les livres contemporains. Ainsi, chaque manuscrit est unique et il est très difficile de dégager des règles strictes applicables à la structure physique de tous les manuscrits. Aussi floues que nous paraissent les règles de mise en page des manuscrits médiévaux, gardons bien en mémoire que ces dernières suivent pourtant une logique adaptée aux conditions d’une autre époque.
Les informations utiles aux chercheurs
Structure de la page
Les premières demandes des médiévistes ont concerné la structuration des documents. Les manuscrits médiévaux sont des objets complexes et la caractérisation de leur structure physique permet de les classer et de les indexer.
Dans un premier temps, les médiévistes ont besoin d’un outil permettant de distinguer les images contenant des enluminures de celles n’en contenant pas. Outre la conséquence évidente d’une telle segmentation en termes d’indexation, cette opération permettrait de recenser les enluminures numérisées uniquement à partir de microfilms et d’engager leur numérisation directe, en couleur.
Une image peut contenir une ou deux pages. Sur chacune des pages de chaque image, il est nécessaire de distinguer la partie contenant le texte du reste (marges, etc.). Dans le corps du texte, il faut ensuite délimiter avec précision les enluminures et les lettrines. Sur chaque page de texte, distinguer le nombre de colonnes et le nombre de lignes par colonne permettrait de restituer la réglure, parfois rendue invisible par le temps. Ensuite, dans les marges, les spécialistes ont besoin de localiser avec précision les notes, dessins et enluminures, et de les identifier.
Selon les manuscrits, une foliotation a été ajoutée en haut à droite de chaque recto, en bas de chaque page ou bien en dessus de chaque colonne. S’agissant d’un ajout structurant, la foliotation relève autant de la structure de la page que du contenu textuel. Après numérisation des documents, les images sont nommées selon un code indiquant la cote du document original ainsi que le numéro de page. Cependant il arrive parfois qu’une page soit manquante ou doublée. Il est donc impossible d’indexer les images par leur nom de fichier ; l’extraction automatique du numéro de folio semble la meilleure solution.

Couleur
La couleur est une donnée importante des manuscrits. Utilisée à des fins de décoration dans les enluminures, elle sert aussi à mettre en avant des éléments textuels (rubriques ou intitulés de début et intitulés de fin, etc.), le plus souvent en l’écrivant en rouge. L’utilisation de la couleur dans le texte peut, dans un certains sens, être comparée à l’usage des styles typographiques contemporains (gras, italiques, souligné).

L’identification de la palette des couleurs d’un manuscrit peut aussi apporter des informations permettant de déterminer le lieu et la date de rédaction de ce dernier. En effet, dans chaque région et pour chaque époque, les produits utilisés pour confectionner les encres diffèrent et ainsi les teintes varient. Cependant, une teinte n’est pas associée à une unique formule et la reconnaissance de la palette des images numériques n’est pas suffisante pour retrouver la totalité des informations sur la pigmentation (utilisation de la spectrométrie, etc.).
Motifs dans l’enluminure
Afin de rapprocher des manuscrits créés à une certaine période, dans une certaine région ou éventuellement par un enlumineur en particulier, il est nécessaire de reconnaître les similitudes de formes dans les motifs ornementaux (entrelacs, ornements, feuilles d’acanthe, etc.). En effet, ces détails sont très spécifiques d’un lieu et d’une époque. Avec la palette de couleurs, ils forment un ensemble de critères permettant de définir l’origine d’un manuscrit.

Certains motifs sont parfois répétés dans plusieurs miniatures ou bien dans les ornements de plusieurs lettres. Il peut s’agir de personnages ou d’animaux dans différentes positions et orientations et il est intéressant de les suivre dans un manuscrit.
De façon plus élémentaire, repérer des formes simples (croix, triangles, cercles) peut permettre d’identifier rapidement certains symboles (auréoles, etc.) ayant une forte importance sémantique.

Écriture
Dans un premier temps, il serait utile de pouvoir rechercher automatiquement certains mots parmi une courte liste, tels incipit, explicit, desinit (avec leurs pluriels incipiunt, expliciunt, desiniunt et leurs abréviations Inc., explic.), Ci commence, Ci fenit, Ci parole, item ejusdem… Ces travaux relèvent de l’analyse du texte au même titre que la transcription. Notons que la transcription des textes ne nous a pas été demandée, ce qui relativise l’importance des données textuelles vis-à-vis des données structurelles et des méta-données.
Dans un second temps, si possible, l’analyse de certaines caractéristiques de l’écriture (module et taille des lettres, hauteur des majuscules par rapport aux minuscules, fréquence des ligatures, etc.) permettrait d’aider au classement des manuscrits dans des groupes géographiques, culturels et temporels. Un tel outil aiderait grandement les paléographes dans leur tâche.
Numérisation
Prise de vue
L’informatique contemporaine est entièrement basée sur un principe de présence (1) ou absence (0) de courant électrique dans des circuits. L’intensité ou la tension de ces courants ne sont pas des données en soi, si bien que les ordinateurs s’appuient sur une logique « tout ou rien ». Un « bit » de données (pour binary element, ou élément binaire) peut donc décrire deux valeurs (0 ou 1, faux ou vrai), deux bits décrivent 4 valeurs, huit bits (un octet) décrivent 256 valeurs, un kilo-octet peut décrire plus de 102466 valeurs différentes. Si l’on conçoit intuitivement qu’il faut plus de place pour encoder un très grand nombre, on ne voit pas nécessairement de façon immédiate qu’il faut aussi une très grande quantité de bits pour décrire une nombre extrêmement petit (naïvement, il suffit de 4 bits pour écrire le nombre 10, mais il faut 15 bits pour écrire 0,00001). Ainsi, ne disposant pas d’une capacité de stockage infinie, un ordinateur est incapable d’appréhender l’infinité de nuances et de détails que l’œil humain perçoit. Les images telles que nous les percevons sont donc hors d’atteinte des machines et pour travailler informatiquement avec des images, il faut d’abord les numériser, c’est-à-dire les transformer en des suites de nombres finis et rationnels.
La méthode de numérisation la plus simple est dite en « niveaux de gris ». On applique sur l’image à numériser une grille et, dans chaque case de cette dernière, la luminosité moyenne est calculée. L’ensemble des valeurs est ensuite stocké dans une matrice. L’image numérique obtenue ne rend alors pas compte des couleurs.
La numérisation en couleur est, pour sa part, basée sur un principe très subjectif et anthropocentrique. L’œil humain ne voit pas toutes les couleurs. Il est composé de capteurs détectant uniquement trois couleurs : rouge, verte et bleue. La synthèse de ces trois données permet de reconstituer une vision personnelle des couleurs. Cette vue que nous nous représentons n’est cependant qu’un aperçu partiel de la réelle étendue du spectre lumineux (un chat, par exemple, peut voir de nombreuses nuances de rouge que nous ignorons, car ses récepteurs rouges sont en outre sensibles à une autre fréquence lumineuse). Les numériseurs couleur plagient l’œil humain. Comme pour la numérisation en niveaux de gris, une grille est posée sur l’image : dans chaque case, trois capteurs enregistrent la luminosité du rouge, du vert et du bleu (ces capteurs sont réglés sur les trois mêmes fréquences que notre œil). Les valeurs obtenues sont enregistrées dans trois matrices. Ainsi, l’image numérique n’est qu’une suite d’octets dans un fichier qui n’a pas de manifestation tangible. L’expression « image numérique » est donc abusive puisqu’il ne s’agit pas d’images au sens visuel, mais au sens analytique du terme. Le terme d’image n’est justifié que par les différents moyens de représentation de ces fichiers dont nous disposons. Les écrans d’ordinateurs (ainsi que les télévisions et les vidéo-projecteurs) restituent ces images à l’aide d’éléments lumineux rouges, verts et bleus, toujours aux mêmes fréquences. Ainsi, théoriquement, du point de vue de la couleur (mais pas de la forme !) une image numérique est censée être perçue exactement comme son modèle.
La numérisation ne vise donc pas à produire la représentation la plus proche possible de l’objet réel, mais la plus proche possible de la perception que nous en avons.
On appelle « résolution » la finesse de la grille utilisée. Cette mesure s’exprime généralement en points par pouce (dpi, pour dot per inch). Plus la résolution est haute, plus l’image numérique obtenue est volumineuse et plus elle est détaillée. L’espace de stockage disponible n’étant pas infini, il faut trouver un compromis entre taille et qualité afin de numériser un maximum d’objets, tout en assurant une précision suffisante pour que les images obtenues soient utilisables. Il n’existe donc pas de « bonne » résolution. Il faut choisir cette dernière en fonction de l’utilisation que l’on compte faire des images numérisées et des contraintes techniques (espace de stockage, puissance des machines, etc.).
Dans la suite de cet article, nous désignerons par « image » une image numérique uniquement. L’objet numérisé sera alors désigné par son nom (livre, photo…).
Stockage
D’ordinaire, les images sont stockées telles quelles dans des fichiers dits « bruts ». Cependant, la taille de ces derniers est alors telle que cette solution ne peut être mise en œuvre pour stocker une grande quantité d’images (une page A4 numérisée en couleur avec une résolution de 300 dpi tient un espace de 25 Mo). Des techniques de compression ont donc rapidement été développées.
La première, intuitive, consiste à remplacer les redondances telles que « 10 10 10 10 » par « (4, 10) ». Cette méthode, nommée RLE, est très efficace sur les images binaires et les images de synthèse, mais n’est pas adaptée aux images de documents qui ne contiennent pas de surfaces unies.
Une famille de méthodes de compression, dite à dictionnaire (dont la plus répandue est LZW), obtient de meilleurs résultats. Ces méthodes parcourent l’image à la recherche de motifs linéaires qui se répètent. Les motifs sont stockés dans un dictionnaire et un numéro leur est affecté. L’image est ensuite encodée, certaines parties étant remplacées par un numéro d’entrée dans le dictionnaire tandis que de longues séquences de pixels sont représentées par un simple nombre. Le taux de compression dépend bien entendu de la présence et surtout de la fréquence des motifs dans l’image.

Pour une taille de fichier minimale, des algorithmes dits à perte ont été créés. Le plus connu et le plus utilisé est JPEG. L’image est découpée en petits éléments carrés de huit pixels de côté. Dans chaque carré, une analyse fréquentielle est effectuée et ce sont non pas les pixels qui seront sauvegardés, mais les fréquences. Les hautes fréquences, c’est-à-dire le bruit mais aussi les détails, sont supprimées, ce qui limite ainsi le nombre de fréquences à sauvegarder. À l’affichage, les fréquences sont à nouveau transformées en pixels. Apparaissent alors des effets de flou et parfois même des brisures horizontales et verticales aux frontières des carrés, car l’analyse fréquentielle dans chacun d’eux est indépendante de leurs voisins. JPEG atteint des taux de compressions très élevés, à condition qu’on accepte la suppression de nombreuses fréquences. La quantité d’information perdue est alors immense et il devient difficile d’appliquer quelque traitement automatique que ce soit à des images ainsi appauvries.
De manière générale, JPEG est un bon format de publication sur l’Internet. Les utilisateurs préfèrent généralement privilégier la rapidité de transfert des images à la qualité de ces dernières, tant que les dégradations engendrées ne sont pas ostensibles. En revanche, pour le stockage des images en vue de leur conservation ou d’un traitement automatisé, il est fortement conseillé d’utiliser des formats de compression sans pertes [Kagan 2001].
D’autres formats de compression avec pertes (tels que Debora [Trinh 2002] et Déjà-vu [Bottou 2000]) ont été développés afin de répondre à la problématique de compression des images de documents. L’idée est de contrôler les pertes d’information afin de conserver les détails caractéristiques du document et d’assurer sa lisibilité. Le principe consiste en une segmentation du texte et un regroupement des caractères par ressemblance afin d’appliquer une compression par dictionnaire. Cela implique bien entendu que le document en question soit imprimé et qu’il soit possible de segmenter correctement ses caractères. Le taux de compression est de loin supérieur à JPEG, ainsi que la qualité de l’image. Ce genre de méthode n’est cependant applicable qu’à un nombre restreint de documents.
Le format PDF a été utilisé pour la diffusion ou le stockage de certains livres. Alors qu’il est adapté aux livres contemporains directement créés en mode numérique, PDF ne se justifie pas pour les documents anciens. En effet, ce format a été créé à l’origine pour les dialogues entre ordinateurs et imprimantes (ou presses). Un fichier PDF contient un ensemble de données vectorielles (comme par exemple des polices de caractères), textuelles et des images. Ces dernières sont généralement encodées en JPEG. Un document manuscrit numérisé ne peut pas être converti en mode texte si bien qu’il sera toujours stocké en mode image dans le PDF, ce qui revient à l’utilisation de JPEG dont nous parlions plus haut.
Nos premiers résultats
Structure de la page
Enluminures
Le repérage des enluminures sur une page peut sembler facile de prime abord. Des tests oculométriques (méthode de suivi du regard) ont montré que, lorsqu’on présente une page d’un manuscrit médiéval à un sujet, ses yeux se tournent vers les enluminures en premier. La taille de ces dernières les rend particulièrement prégnantes et on pourrait se laisser aller à penser qu’un simple filtrage des objets présents sur la page en fonction de leur taille suffirait à les extraire. C’est compter sans les différentes causes de dégradation de la qualité des images, allant de l’état original des manuscrits à la numérisation de microfilms. En effet, si on se contente de définir une enluminure comme un objet de grande taille par rapport au texte, cette définition convient tout aussi bien aux taches. De plus, les hampes et jambages de deux lignes successives peuvent se croiser ou se toucher et les notions même de mot ou de caractère, en termes de pixels, deviennent difficiles à appréhender. À tout cela s’ajoute la grande variabilité des enluminures, qui en fait des objets très difficiles à décrire. Faites tantôt de traits fins et entrelacés, tantôt de traits droits et épais, souvent d’une couleur différente de celle du texte, parfois multicolores, il est impossible de construire un modèle informatique stable de l’objet « enluminure ».


Des recherches sont menées depuis plusieurs années dans le cadre d’extraction d’enluminures dans les livres imprimés du xvie siècle. Cette problématique est autrement plus simple que pour les manuscrits médiévaux, et pourtant aucune solution entièrement satisfaisante n’a encore été découverte.
Au cours du projet, plusieurs pistes ont été explorées. Pour les manuscrits numérisés en couleur, une simple analyse de la saturation et de la luminosité permet de séparer le texte en noir du texte en couleur et les enluminures. La taille des éléments extraits permet ensuite de séparer le texte des enluminures. Ce procédé ne peut cependant être appliqué qu’aux images en couleur provenant de manuscrits en bon état (sans taches, ni trous, etc.), c’est-à-dire à une petite fraction de la masse que nous avons à traiter…
Une autre solution, basée sur la différence de taille entre les enluminures et les caractères, a été rapidement mise en échec dans les microfilms les plus dégradés. En effet, les taches et déchirures fréquentes lient des lignes entre elles et forment des objets géométriques de même taille que les enluminures. Des méthodes basées sur l’analyse de la courbure et de l’orientation des lignes permettent d’extraire les enluminures les plus carrées, car lesdites caractéristiques sont alors très différentes de celles du texte ; mais de telles enluminures ne représentent pas la majorité des cas. La largeur des traits peut aussi permettre une discrimination des objets sur la page, mais, encore une fois, les enluminures ne sont pas toutes à traits larges.

La piste la plus prometteuse découle de la première remarque que nous avons effectuée sur les enluminures : elles sont prégnantes. La théorie de l’espace multi-échelle [Lindeberg 1994] est un paradigme mathématique s’inspirant de la vision humaine.
Le principe de la théorie de l’espace multi-échelle consiste à étudier une image que l’on regarderait en se plaçant de plus en plus loin d’elle. Cela est représenté par des lissages successifs de l’image via un filtrage gaussien. La représentation d’échelle σ d’une image Ι est donc obtenue ainsi :
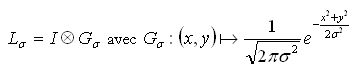
Plus σ est grand, plus la représentation de l’image se trouble, ce qui correspond à regarder l’image de plus en plus loin.
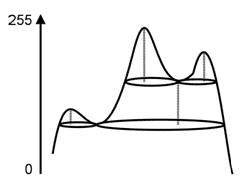
De façon générale, la représentation à une échelle donnée est analysée à travers ses « blobs ». Intuitivement, les blobs sont les taches floues que l’on perçoit sur l’image filtrée. Ils sont définis par leur hauteur et leur largeur. Une coupe des blobs peut être effectuée en seuillant l’image filtrée avec une valeur fixe. L’analyse des différentes échelles permet de faire ressortir la hiérarchie des structures portées par une image.
En appliquant un lissage directement sur les images en niveaux de gris, nous remarquons que les blobs les plus hauts correspondent aux lettrines. Il est aisé de déterminer visuellement un seuil tel que seuls ces blobs apparaissent. Cependant, seuiller automatiquement cette image filtrée n’est pas simple.

Le nombre de blobs à un seuil donné est une mesure simple mais qui s’est avérée porteuse d’informations. Le graphe associé contient toujours un gros mode pour les seuils bas puis un ou plusieurs petits modes. Il s’est avéré que la vallée entre le premier gros mode et le suivant correspondait la plupart du temps avec le seuil d’extraction des lettrines.
Nous avons donc implémenté un seuillage selon le critère « seuil correspondant à un minimum local du nombre de blobs ». Les blobs touchant les bords de l’image sont automatiquement supprimés car ils correspondent au support du livre lors de la prise de vue.
Il est possible d’obtenir plusieurs seuils. Une telle décomposition se justifie par la complexité des manuscrits médiévaux. Chaque manuscrit est caractérisé par une signature propre qu’il est impossible de généraliser. Un unique critère ne suffit donc pas à décrire la réponse de l’ensemble des manuscrits médiévaux au filtre proposé. Une décomposition de ces manuscrits en plusieurs groupes, qui suivent chacun un comportement comparable, est envisagée mais nécessitera une étude à très large échelle.
La détection de plusieurs seuils peut être due à un bruit quelconque. Dans ce cas, les seuils correspondent à la même structure.

La détection de multiples seuils peut aussi être caractéristique d’une décomposition hiérarchique du document (voir figure ci-dessous). Sur cette image, les lettrines de différentes tailles disparaissent tour à tour lorsque le seuil augmente, impliquant quatre détections automatiques de seuil. Une lettrine n’est pas détectée sur la première image car elle est accolée au blob périphérique qui est automatiquement supprimé.

Les résultats obtenus sont très bons, compte tenu de la nature prospective de l’étude menée ici et de la complexité du problème posé. La méthode a été testée sur d’autres images provenant de manuscrits très différents les uns des autres et donne à chaque fois des résultats similaires.
Ces résultats nous confortent dans notre volonté de poursuivre nos investigations sur la piste de la représentation multi-échelle. Dans des travaux à venir, avant de remettre en cause le calcul de multiples seuils, il devrait être possible de réduire le nombre de fausses détections en effectuant une analyse pyramidale des blobs en fonction des seuils.
Structure physique
Au Moyen Âge, le parchemin fut longtemps le support principal des documents mais il n’en était pas pour autant bon marché. La volonté d’économie se traduisait par une utilisation maximale de la surface de la page et parfois même par la réutilisation d’anciens parchemins après grattage (palimpsestes). La notion de paragraphe n’étant donc pas encore établie, le texte était souvent écrit linéairement, sans sauts de lignes (et encore moins sauts de pages) entre les différentes parties d’un exposé ou d’un récit.
Les grandes divisions du texte (livres, chapitres, paragraphes…) étaient indiquées par des phrases, souvent colorées, qui n’étaient pas nécessairement numérotées. Ainsi, pour repérer une partie d’un texte, il n’est pas possible d’utiliser des numéros de livres, chapitres ou paragraphes, qui sont des indicateurs de position de type logique, mais il faut se référer aux numéros de feuillet, de colonne et de ligne, indicateurs de position de type physique.
D’autre part, la segmentation automatique des colonnes et le comptage des lignes pour chaque colonne permet de réunir des ensembles de manuscrits susceptibles d’avoir été produits dans un même temps et lieu, selon les mêmes usages. En effet, ces éléments de mise en page, au même titre que le style des enluminures, pourraient s’avérer caractéristiques d’une région (ou d’un scriptorium) et d’une période. Le comptage des colonnes et des lignes, associé à des études paléographiques et à l’analyse de formes et couleurs des enluminures pourrait permettre d’aider à la localisation des manuscrits. C’est donc là un travail que les médiévistes nous ont demandé de réaliser.
Délimiter automatiquement les zones de texte dans une image de manuscrit peut poser un certain nombre de problèmes. En effet, même si les textes dans la marge (notes, gloses, etc.) sont en général suffisamment petits pour ne pas interférer, les déchirures, les taches et la prise de vue du livre ouvert dans sa globalité (la tranche des pages précédentes et suivantes ainsi que la couverture peuvent être facteurs d’erreurs de détection, l’ombre de la reliure au milieu est tantôt invisible, tantôt invasive) rendent cette étape inégalement simple ou délicate. La qualité de tous les résultats suivants dépend de la pertinence de cette phase qui est l’une des premières dans la détection de la structure physique.
La première étape dans l’extraction de la structure physique consiste à détecter la ou les zones de texte. Une zone de texte est une surface de l’image qui contient des mots. Un mot se définit comme une suite de lettres et donc par transitivité, une zone de texte est une surface dense en caractères (lettres). Cette caractéristique a valu aux images de documents le nom d’images de traits. Lorsque cette propriété disparaît, la plupart des approches de traitement d’images de documents deviennent caduques. La présence de taches, la compression JPEG, la dégradation des supports originaux (microfilms) et la complexité des formes (hampes et jambages qui s’entrecroisent et se touchent) empêchent l’extraction précise des caractères.
Nous définissons une colonne de texte comme une zone qui contient une forte densité de symboles, par opposition avec les zones vides (blanches) et les zones d’ombres (reliure, couverture, support, etc.) de l’image. Les symboles sont des objets sombres sur fond clair qui se caractérisent par un grand nombre de transitions noir–blanc et blanc–noir. Pour rendre compte de cette particularité, nous avons utilisé la magnitude du gradient.
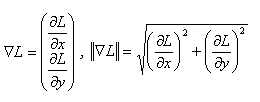
En effet, dans les zones à fort contraste, le gradient prend des valeurs élevées ; dans les zones relativement unies, sa valeur est quasiment nulle.
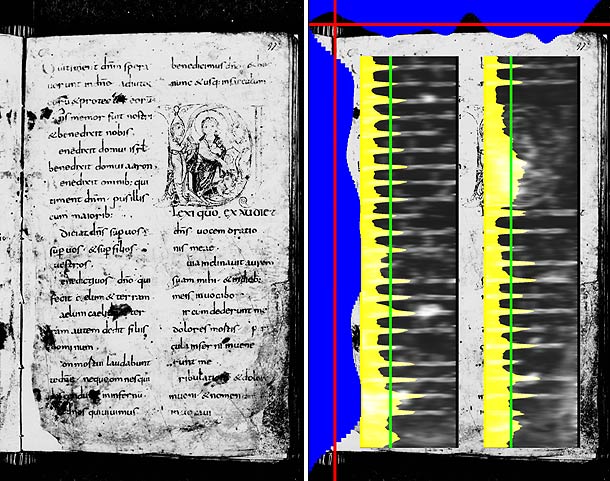
Nous effectuons ensuite les projections horizontale et verticale des valeurs de la magnitude du champ des gradients. Ces projections sont réalisées dans un espace réduit d’un facteur 8 sur l’axe des abscisses et d’un facteur 16 sur l’axe des ordonnées. Cela nous permet d’estomper les détails et ainsi de supprimer les causes d’éventuels effets de bords générateurs de dysfonctionnements. Le facteur de division selon l’axe des abscisses est plus petit, car nous avons besoin d’une plus grande précision selon cet axe, étant donné que ce sont des blocs verticaux que nous voulons extraire. Afin de mieux faire ressortir les zones de fort contraste, lors de la réduction de l’image des magnitudes du champ de gradient, nous utilisons l’opérateur max plutôt que la moyenne.
Les projections obtenues, qui se présentent à la façon d’histogrammes, sont ensuite lissées. La projection horizontale contient généralement un mode et la projection verticale contient autant de modes qu’il y a de colonnes. On calcule un seuil sur chaque projection grâce à l’algorithme de Fisher (appliqué aux valeurs et non aux indices comme il est d’usage) et on génère des surfaces dans les zones où les projections sont supérieures à leur seuil respectif. Des modes parasites peuvent apparaître et engendrer des zones non désirées. Ces dernières sont supprimées en fonction de leur surface.
À l’intérieur de chaque colonne, on effectue un lissage horizontal sur l’image en niveaux de gris. Cette opération a un effet similaire à un déplacement latéral de l’objectif lors de la prise de vue ; il en résulte donc une concentration de l’information à mi-hauteur des lignes. Les pixels sont ensuite projetés horizontalement, c’est-à-dire que l’on somme l’intensité de chaque pixel sur une même ligne. Un seuillage de Fisher permet ensuite de déterminer la position approximative des lignes et de les compter.
Dans un second temps, nous avons appliqué la théorie de l’espace multi-échelle décrite précédemment, non pas directement à l’image en niveaux de gris, mais à une vue de la texture de l’image. Cette dernière est réalisée en calculant la variance directionnelle locale, c’est-à-dire la variance de l’angle du gradient dans une fenêtre autour de chaque point. Les résultats sont cette fois-ci plus difficiles à interpréter. Nous donnons ici deux exemples ouvrant différentes perspectives.
Sur le document présenté ci-dessous, un seuillage manuel permet de faire ressortir la décomposition de l’image en deux parties. Le filtre réagit ici à l’alternance de lignes de texte et de partitions musicales. Le haut de la partition de la première colonne est mal détecté car le texte intercalé est partiellement effacé, rendant les mesures plus chaotiques.

La figure suivante présente l’image d’un manuscrit glosé. Le filtre a ici réussi à séparer le texte des gloses (aussi bien en marge qu’entre les lignes) du texte principal. Le seuil a été choisi manuellement et semble ne pas être totalement adapté à toutes les parties de l’image. L’utilisation d’un seuil local pourrait peut-être permettre d’augmenter la précision de la segmentation.
Cette méthode demande certes à être améliorée, mais elle constitue une solution alternative à l’analyse des connexités sur les manuscrits dégradés. Il serait en effet impossible d’effectuer un filtrage du texte selon la hauteur des caractères sur cette image.

Foliotation
Les manuscrits médiévaux étaient généralement constitués de cahiers, c’est-à-dire de grandes feuilles de parchemin ou papier pliées en deux, en quatre, ou en huit. Il était possible de numéroter, au choix, les pages — on parle alors de pagination — ou les feuillets (ou folios) — on parle alors de foliotation. Le second choix était le plus usité. Les numéros pouvaient être notés de diverses manières, en nombres romains ou arabes, plus rarement avec des codes alphabétiques.
Pour diverses raisons, une foliotation moderne a souvent été ajoutée ou créée par des conservateurs aux époques moderne et contemporaine : des numéros manuscrits ont été apposés, généralement dans le coin supérieur droit des pages de droite. Cette numérotation peut cependant varier dans son emplacement (folios notés en bas…) ou dans son principe (numérotation de chaque colonne, etc.). Elle était généralement notée au crayon ou à l’encre.
Lors du microfilmage d’un document, il peut arriver que certaines pages soient photographiées deux fois (soit par inadvertance, soit suite à un recalibrage de la machine), ou bien qu’une page soit oubliée (pages collées, mauvaise manipulation, etc.). Il peut en être de même lors de la numérisation directe. Les microfilms étant numérisés de façon très automatisée, les effets ne s’ajoutent généralement pas. Quoi qu’il en soit, l’ordre des fichiers images et leur nom ne sont pas linéairement liés aux folios. Il est donc impossible d’associer chaque image au folio qu’elle représente sans analyser ladite image et reconnaître l’inscription manuscrite du conservateur.
Dans l’absolu, la reconnaissance des numéros de folio pourrait être associée à l’analyse du texte et à la reconnaissance des caractères ou des mots. Cependant, elle doit en être distinguée pour deux raisons : d’abord les signes de foliotation ou pagination appartiennent à une autre époque que le texte (manuscrits foliotés longtemps après le travail de l’ouvrage), surtout la foliotation a un rôle très structurant. Afin d’ordonner notre exposé selon le point de vue de l’utilisateur, nous avons donc préféré classer cette section dans le domaine de la reconnaissance de structure.
La reconnaissance de chiffres manuscrits est un domaine qui a atteint sa maturité. Des systèmes de lecture de chèques automatiques fonctionnent avec de bons résultats, mais ces systèmes ont demandé de longues années de travail. Les systèmes de reconnaissance de chiffres usuels portent principalement sur des documents contemporains et très récents (chèques, factures, etc.). Pour cela, ils se fondent sur de très grandes bases d’apprentissage, ce qui leur permet de modéliser un très grand nombre de variations des mêmes symboles. Afin de reconnaître les numéros de folio, nous nous sommes inspirés des techniques classiques que nous avons adaptées au contexte. En effet, l’écriture des folios est stable sur un même manuscrit, mais peut varier énormément d’un document à l’autre. De plus, le style d’écriture est très différent de celui d’aujourd’hui et les bases d’apprentissage existantes ne conviennent pas à notre cas. Nous aurions pu nous servir de la réclame pour vérifier que l’enchaînement des pages est correct, mais cela serait revenu à un problème de comparaison de mots, plus complexe que la reconnaissance de chiffres. Notons aussi que tous les manuscrits ne possèdent pas de réclame.
Préalablement au traitement d’un document, l’utilisateur doit fournir un certain nombre de paramètres. Une base de dessins de chiffres sera sélectionnée et chargée, selon la graphie des folios. Cette base contient un ensemble de caractères de référence. Le traitement sera semi-automatique car les situations posant des problèmes sont parfois assez complexes et seul l’opérateur peut prendre la décision adéquate. Lors du traitement, chaque caractère de folio sera comparé aux caractères de cette base afin d’inférer son étiquette. Cette base doit donc rester petite afin d’optimiser la vitesse de traitement, ce qui explique notre choix de séparer des bases de caractères selon chaque police pour les imprimés ou selon le style d’écriture pour les manuscrits.
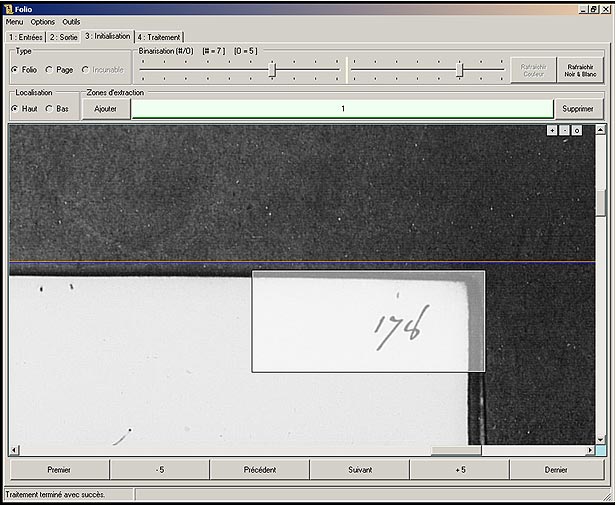
Selon le type de document, les numéros de feuillet peuvent se trouver à divers endroits et en différents nombres (en haut à droite de la page de droite, en bas de chaque page, en haut de chaque colonne, etc.). Notre outil détermine automatiquement le haut et le bas de chaque page, ainsi que la reliure entre les deux pages (respectivement, le centre de la page, s’il n’y en a qu’une). L’utilisateur trace avec la souris la ou les zones qui sont susceptibles de contenir des folios. Ces zones sont localisées relativement aux repères précédemment calculés afin de ne point pâtir d’un éventuel déplacement du livre sur son support lors de la numérisation.
Le processus étant semi-automatique, nous avons choisi une méthode de binarisation globale pour sa rapidité. L’inconvénient de telles méthodes est le manque de précision. Pour remédier à ce défaut, l’utilisateur règle lui-même deux paramètres de binarisation afin de pouvoir vérifier visuellement la pertinence de cette dernière.
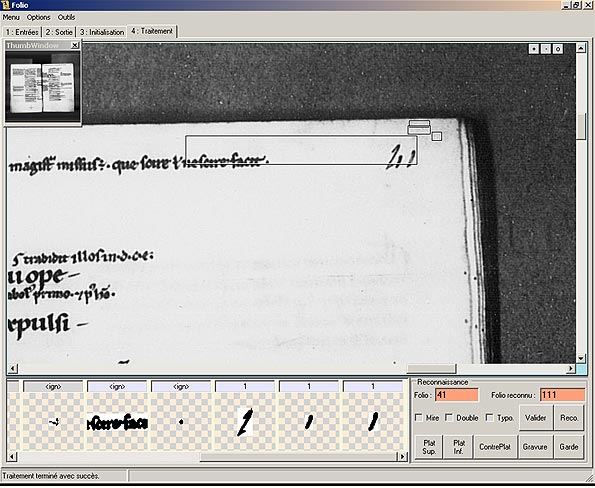
Lors de la phase de traitement proprement dite, un système de comptage est confronté avec les résultats de la reconnaissance de caractères. Si le folio reconnu est égal au folio attendu déterminé par comptage, le résultat est sauvegardé automatiquement dans un fichier XML. Le cas échéant, le traitement se met en pause et l’utilisateur doit résoudre le conflit. Ce dernier peut être dû à une mauvaise reconnaissance d’un caractère (auquel cas l’utilisateur peut choisir de l’ajouter à la base de connaissance), à une dégradation locale du document, à une faute de typographie (que l’utilisateur peut signaler et qui sera notée dans le fichier XML), ou bien encore à l’absence de foliotation (auquel cas l’utilisateur peut indiquer s’il s’agit d’une page de garde, d’un plat ou contreplat, etc.)
Couleur
Les différentes couleurs présentes sur un manuscrit ainsi que leur distribution sur la page sont le reflet de leur usage. Notre intérêt pour la couleur se justifie par deux raisons. Les objets colorés présents dans un manuscrit médiéval sont principalement les enluminures et les titres de rubriques. Or ces deux types d’éléments sont particulièrement structurants et leur extraction est une priorité. D’autre part, la couleur intrinsèque de la page peut se révéler une information très importante. Prenons l’exemple d’un manuscrit taché d’eau : sa lisibilité est donc compromise. Détecter les zones tachées et les restaurer, sans pour autant altérer le texte, nécessite une description précise des couleurs de l’image.
Ainsi la couleur d’un manuscrit médiéval revêt à la fois un aspect structurant et un aspect caractérisant. Cette double fonction justifie d’autant plus que nous étudions les couleurs de ces images.
Une image en couleur peut contenir jusqu’à 65 000 fois plus d’information qu’une image en niveaux de gris. La majorité des œuvres numérisées par l’IRHT provient de microfilms. Les images en couleur sont certes plus rares, mais nous pouvons profiter de la qualité de numérisation de ces quelques manuscrits pour appliquer des traitements plus pointus.
La couleur constitue en effet une donnée et une métadonnée très informative. Les phrases importantes et les transitions sont souvent écrites en rouge, ce qui fait de la couleur une donnée au même titre que le gras ou l’italique dans les livres contemporains. La couleur des enluminures est une métadonnée puisqu’elle nous donne des indications sur le lieu et la date de fabrication du manuscrit. De plus, la précision dans la description de la couleur de chaque pixel peut permettre, dans certains cas, d’atténuer ou de supprimer certaines dégradations de l’image, comme par exemple l’apparition du verso en transparence ou la présence de tâches d’humidité.
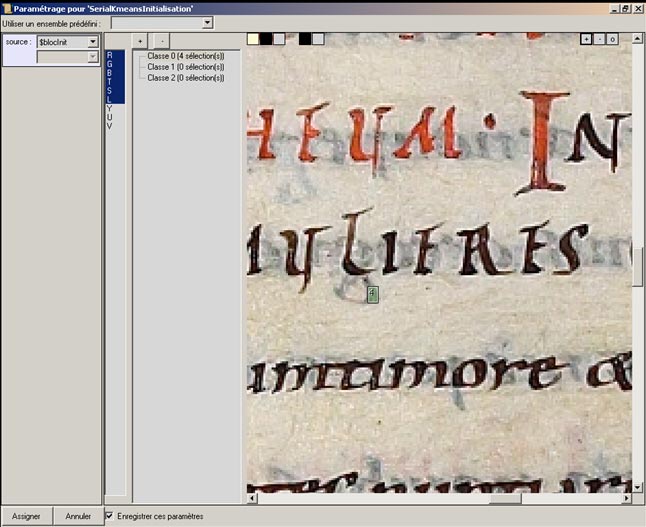
Notre méthode de segmentation [Leydier 2004], spécialement développée pour les images de documents, s’inspire des techniques de binarisation locales. Un modèle des couleurs du document est créé par l’opérateur. Ce modèle sera ensuite adapté au contexte de chaque pixel. Le pixel est ensuite classifié selon ce modèle et finalement une image contenant plusieurs plans (ou calques, dans le champ sémantique de la retouche d’images numériques) correspondant aux différents éléments décrits dans le modèle.
Dans un premier temps, l’utilisateur choisit le nombre de classes dans lesquelles il veut diviser les images. Cette opération n’a lieu qu’une seule fois pour un même livre. Si on souhaite séparer le fond de la forme, on crée deux classes (ce qui revient à binariser) ; si on souhaite séparer les zones colorées, on créera autant de classes que de couleurs (fond, noir, rouge, bleu, etc.). Pour chaque classe, il sélectionne à la souris un ou plusieurs rectangles sur une image du livre. Ces échantillons seront utilisés pour représenter chaque classe. Une fois toutes les classes décrites par des exemples, le traitement automatique commence.
En résumé, notre algorithme suit la marche suivante. Soit la ƒ fonction que l’on applique à un point P pour obtenir son vecteur de caractéristiques. Pour chaque fenêtre Wpcentrée sur P, nous calculons d’abord les nouveaux centres des nuées par un algorithme k-means classique. Le point précédant P est noté P–, les centres de la fenêtre sont notés
![]() , l’opérateur de moyenne associé à l’espace de caractéristique induit ƒ par est noté μf.
, l’opérateur de moyenne associé à l’espace de caractéristique induit ƒ par est noté μf.
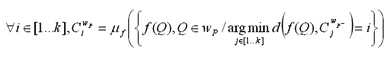
Nous empêchons ensuite les centres de se croiser en les ramenant aux centres de référence s’ils bougent trop. Les centres initiaux donnés par l’opérateur sont notés ![]() .
.
Finalement, nous classifions le point P :
Une fois les calculs terminés, l’utilisateur peut reconstruire de nouvelles images, par exemple en remplaçant une classe par sa moyenne pour supprimer un fond trop bruité (voir ci-dessous), ou bien remplacer chaque classe par sa moyenne pour obtenir un affichage stylisé de la segmentation.

Notre méthode peut aussi être utilisée pour mettre en valeurs certaines propriétés de la disposition ou de l’utilisateur des couleurs dans un document. Le résultat n’est alors pas lisible en termes de texte, mais offre une meilleure vue de l’utilisation de la palette.

Motifs dans l’enluminure
Nous avons décrit plus haut les difficultés qui se présentent pour repérer les enluminures dans une page de manuscrit médiéval. Ces mêmes difficultés réduisent d’autant les possibilités de reconnaître des formes à l’intérieur de ces dernières. En effet, avant de comparer des éléments présents dans une enluminure, il faut pouvoir délimiter ses frontières. Ensuite, il faut être capable de décomposer les motifs qu’elle contient de façon cohérente. Or, la complexité de certaines enluminures ainsi que les dégradations subies à travers le temps et lors de la numérisation ne permettent pas toujours une telle segmentation. Le problème se pose alors dans ces termes : comment comparer des motifs de taille et de forme inconnues, situés à des endroits indéterminés ?
Le problème peut être réduit à un ensemble de sous-problèmes plus simples. Si l’on est capable de modéliser un motif à partir d’éléments géométriques simples (ex : un rond pour une auréole), il est envisageable de pouvoir les rechercher automatiquement. Il faut cependant noter que le domaine de la géométrie discrète (les règles applicables à la géométrie sur papier ne sont pas toutes applicables aux pixels) est encore jeune et que la définition même d’un cercle discret reste sujet à débat. De plus amples investigations sur cette voie seront effectuées dans de futurs travaux.
Écriture
Localisation de mots
Certains mots jouent un rôle important dans les manuscrits médiévaux, comme par exemple « incipit » et « explicit » qui bornent les chapitres ou les livres dans un même volume. De manière plus générale, l’accès au contenu textuel des documents du patrimoine a trois principales applications :
- La première, la plus intuitive, est le butinage. Si un historien désire se documenter sur la vie d’un personnage particulier, il doit feuilleter tous les livres pour chercher les quelques passages traitant de son sujet. Une recherche automatique de quelques mots pourrait faire gagner beaucoup de temps.
- Dans le cas de collections thématiques, certains mots-clés ont une importance particulière. Ces derniers peuvent constituer des points d’entrée à quiconque chercherait à explorer les documents de la collection. Afin d’indexer ces derniers, il faut pouvoir chercher automatiquement toutes les occurrences des mots-clés en question.
- Dans le cadre de la traduction d’un texte en langue ancienne ou de la transcription d’un texte très peu lisible, il peut s’avérer nécessaire de rechercher d’autres occurrences d’un mot que l’on ne comprend pas. Ainsi, à partir des différents contextes de son utilisation, il est possible d’inférer son sens. Là aussi, un outil de recherche automatique permettrait un très grand gain de temps.
Chacune des applications de la recherche textuelle dans les documents anciens se décline en trois usages différents :
- Le premier usage est la simple recherche d’un mot. Les usages suivants forment en quelque sorte un traitement supplétif à dernier.
- Il peut s’avérer nécessaire de chercher diverses formes dudit mot, selon les déclinaisons ou conjugaisons applicables. Un système d’accès au contenu textuel suffisamment souple permettrait de rechercher des racines de mots afin d’en trouver toutes les formes possibles.
- Puisqu’il est possible de rechercher un mot, rien ne s’oppose à chercher des propositions entières. De même, la recherche simultanée de plusieurs mots permet de créer des statistiques de co-occurrences importantes pour les linguistes.
Il est cependant impossible d’appliquer une reconnaissance de caractères (OCR) à des manuscrits. Les logiciels d’OCR disponibles dans le commerce sont en effet dédiés aux documents imprimés contemporains (fax, lettres d’entreprise, factures…) et les technologies utilisées sont incompatibles avec la structure des manuscrits médiévaux. Une solution a déjà été proposée pour une problématique similaire, les notes de George Washington [Rath 2002], mais cette dernière repose sur une segmentation en mots : l’utilisateur choisit un mot qu’il veut rechercher et celui-là est comparé avec tous les autres mots qui ont été extraits automatiquement du document. Une telle opération est impossible dans notre cas car nos documents sont trop hétérogènes pour envisager une solution simple et efficace. Notons que si segmentation des mots il y a, cette dernière doit être parfaite car tous les résultats suivants en découlent. Ne pouvant nous engager à fournir une telle segmentation, nous avons développé une nouvelle méthode [Leydier 2005] dans laquelle le mot recherché est comparé à chaque page et non pas à chaque autre mot.


Comme dans toute méthode de ce type, l’utilisateur détoure un mot sur une page à l’aide de la souris et ce mot sera ensuite recherché. Une liste de mots est ensuite présentée à l’utilisateur qui devra trier les bons résultats et les mauvais. Moins cette liste contiendra de mauvaises réponses, plus le logiciel sera considéré de bonne qualité et utile. De même, plus les bonnes réponses seront groupées dans la liste, plus il sera facile à l’utilisateur de les trier.
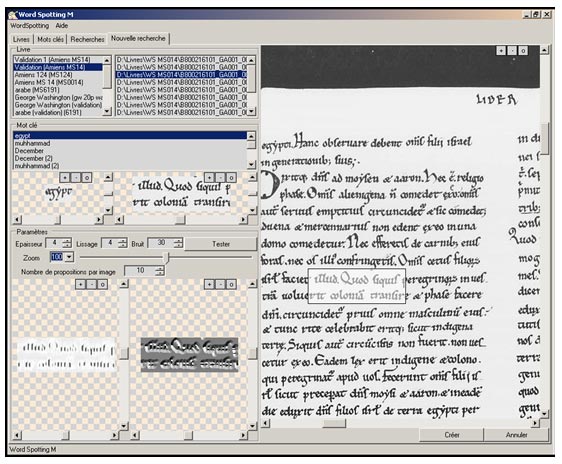
Notre solution ne porte pas sur des mots mais sur la page (ou double-page) dans son intégralité ; aussi la première étape consiste-t-elle à déterminer quelles régions de la page son susceptibles de contenir des mots. Pour cela, nous appliquons un traitement qui fait disparaître les traits les plus fins, laissant ainsi une sorte de signature du texte. Les courts traits épais qui restent seront utilisés comme guides pour la recherche. Le mot recherché est découpé de la même façon. Seules les parties d’images autour des guides seront comparées, ce qui autorise une certaine élasticité et permet de trouver des occurrences de mots écrites de façons plus ou moins serrées. De plus, ne comparer le mot recherché qu’à une partie de chaque page réduit considérablement le temps de calcul.
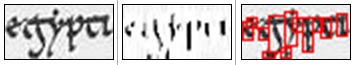
Finalement, les pixels autour des guides ne sont pas comparés tels quels. Une transformation préalable est effectuée en extrayant les gradients : 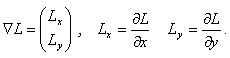 Ce calcul permet de ne pas comparer des points plus ou moins noirs ou blancs entre eux mais de comparer la courbure locale du motif autour ce chaque point. Cette représentation est porteuse de beaucoup plus d’information et permet une comparaison plus précise des formes.
Ce calcul permet de ne pas comparer des points plus ou moins noirs ou blancs entre eux mais de comparer la courbure locale du motif autour ce chaque point. Cette représentation est porteuse de beaucoup plus d’information et permet une comparaison plus précise des formes.

Ci-dessous suit un exemple de recherche effectuée sur le mot « egypt » dans le manuscrit 14 de la Bibliothèque municipale d’Amiens. Les résultats sont triés selon un ordre de pertinence décroissant.
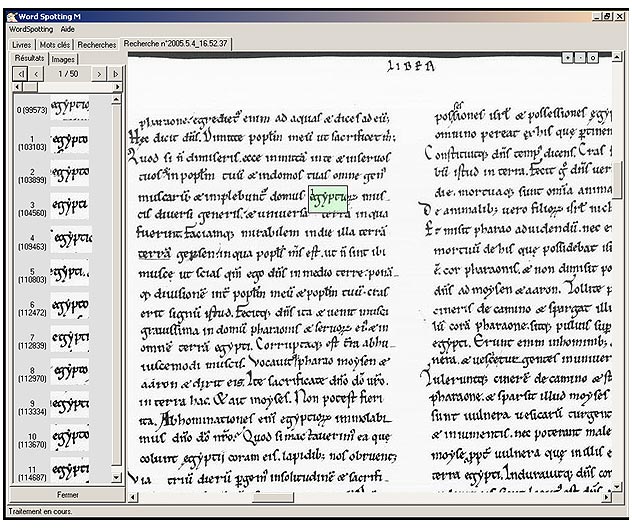
Les résultats sont excellents, tant en termes de précision (mesure du nombre d’occurrences du mot-clé localisées rapportée au nombre de mots localisés) qu’en termes de rappel (mesure du nombre d’occurrences du mot-clé localisées rapportée au nombre d’occurrences réelles de ce mot dans le texte).
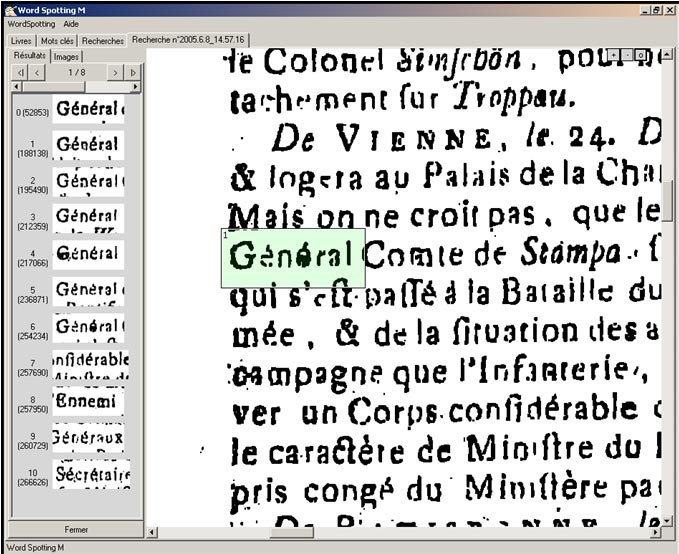
Nous avons ensuite testé notre méthode sur une image que nous avons volontairement dégradée. La réponse montre la stabilité de notre système, même en présence de dégradations sur les documents.


Des tests ont aussi été conduits sur des imprimés français très dégradés. Les résultats sont de loin supérieurs à ceux qu’auraient obtenus des logiciels d’OCR commerciaux.
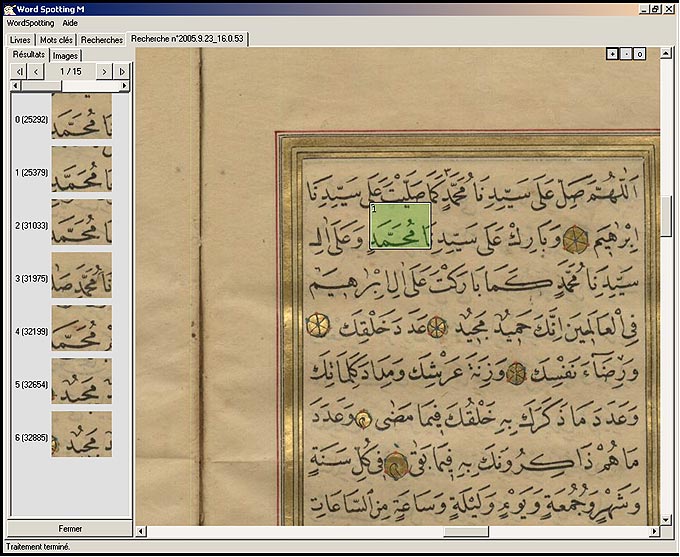
La méthode fonctionne partiellement sur les manuscrits arabes et tibétains ; des tests sont en cours sur des manuscrits chinois et japonais.
Au final, malgré un paramétrage assez lourd, notre méthode offre des résultats convaincants, que nous travaillons à améliorer encore.
Dans la suite de nos travaux, nous envisageons de réduire la principale limitation de localisation de mots : il est nécessaire de trouver manuellement une occurrence du mot-clé afin de pouvoir lancer la recherche. Nous pensons proposer à l’opérateur de générer des prototypes en les saisissant au clavier. Cela implique d’avoir préalablement extrait des images du livre plusieurs occurrences de chaque lettre de l’alphabet (utiliser une police vectorielle est en effet hors de question car seuls quelques rares styles d’écriture sont représentés, et de façon trop idéale par rapport à la réalité des images). Ce travail ne pourra être effectué qu’avec l’aide de paléographes car composer des mots à la manière d’un manuscrit médiéval n’est pas aussi simple qu’accoler des lettres les unes derrière les autres…
Une autre utilisation de notre technique pourrait être de créer un glossaire des mots utilisés dans un manuscrit ou bien encore de classer les mots par fréquence d’apparition. De telles applications nécessitent cependant de définir des termes, soit en segmentant les documents en mots, soit en utilisant un dictionnaire.
Caractérisation de l’écriture
De l’étude de l’écriture en tant qu’objet graphique, et non en tant que représentation d’une pensée, il est possible de tirer de nombreuses informations sur la date et le lieu de création d’un manuscrit. Différents styles d’écriture ont coexisté et évolué en même temps, se mélangeant parfois et rendant ainsi plus difficile le travail de classification.
Conclusion et perspectives
De nombreuses questions étaient à l’origine du projet « Formes et couleurs des manuscrits médiévaux ». Un grand nombre de pistes ont été explorées du côté de l’informatique afin d’y apporter des réponses. Ces travaux se veulent plus prospectifs qu’applicatifs et ont donné lieu à un examen en largeur d’abord des possibilités qui s’offraient à nous. Ainsi, certaines idées qui nous paraissaient acquises au début du projet – comme l’extraction des enluminures – se sont révélées extrêmement difficiles à mettre en œuvre, tandis que des réalisations qui nous semblaient hors d’atteinte – telles que la localisation de mots – ont pu être accomplies.
Toutes les questions n’ont donc pas trouvé de réponse, mais la plus importante en a reçue une : médiévistes et informaticiens peuvent travailler ensemble pour créer des outils de recherche adaptés à l’étude des manuscrits du Moyen Âge.
Le projet arrive à son terme, mais pas notre collaboration. Dans les années qui viennent, de nombreuses idées seront approfondies et de nouveaux thèmes seront abordés collectivement.
À court terme, des questions d’ordre pratique se poseront : comment valoriser nos travaux ? Comment les diffuser et à qui ? Pour répondre à ces questions il nous faudra créer une nouvelle terminologie, commune à tous les membres de l’assemblée, afin de ne pas s’exposer aux risques d’incompréhension provenant du caractère polysémique qui fait la richesse même de ce langage dont nous tentons de préserver l’histoire.