Table des matières
- Les problèmes posés
- Un système d’indexation par le contenu pictural
- Deux exemples
- Perspectives
- Annexe 1 : Les partenaires du projet
- Bibliographie
Les problèmes posés
Une base d’images indexées sémantiquement
Dès sa création1, la vocation première de la photothèque du CESCM repose sur la mise à disposition des enseignants, chercheurs et étudiants en civilisation médiévale d’un fonds iconographique consacré à l’art roman. Ce fonds est constitué de plus de 150 000 documents2. Il doit notamment ses origines à de nombreux dons, des achats réalisés auprès de photographes professionnels, d’institutions ou éditeurs spécialisés. Puis dès 1990, les campagnes d’acquisition ont été conduites par Jean-Pierre Brouard, photographe professionnel recruté au CESCM.
Pendant de nombreuses années, la consultation de la collection s’est effectuée à partir d’un fichier manuel thématique ou à partir d’une recherche de type « topographique » dans la salle d’archives. Ce système au départ précurseur, est rapidement devenu obsolète avec l’arrivée des nouvelles technologies.
Dès 1994/95 l’accent est mis sur les missions photographiques pour les monuments, leur décor et les peintures murales. À partir de 1997, une gestion électronique du fichier thématique et du fonds d’images est étudiée. Deux bases en découleront, la première, « Romane », est une base de type monographique ayant pour objectif de présenter l’intégralité du fonds sous la forme d’un contenu textuel associé à une ou plusieurs images.
La seconde, Peinture, est une base de type iconographique. Sa conception est liée au projet d’inventaire des peintures murales romanes de France3. L’établissement d’une base de données à la fois photographique et textuelle suffisamment précise et exhaustive a pour but de faciliter tout type de recherche sur les peintures murales romanes ou sur le monument dans son ensemble.
L’architecture et l’interface des deux bases ont été pensées de la même façon, intégrant un thésaurus hiérarchisé et une grande diversité de champs relatifs à la topographie, au vocable, à l’emplacement, à la datation du sujet traité mais également aux thèmes, à la description, à l’épigraphie… Des renseignements sur le document proprement dit sont également intégrés, comme par exemple l’auteur du cliché et la date de prise de vue.
L’interface exploite à la fois un gestionnaire de données textuelles et un logiciel serveur de documents multimedia4. L’ensemble de ces outils permet à l’utilisateur d’effectuer soit une recherche simple guidée par formulaire, soit une recherche par combinaison logique de rubriques (opérateurs ET, OU, égalité, inégalité) ou une recherche globale multi-critères.
Images et index sémantiques
Chaque campagne d’acquisition suit un protocole précis et complet. Dans le domaine des peintures murales, les prises de vues doivent impérativement intégrer le contexte architectural dans lequel s’inscrit l’œuvre, les irrégularités du support et son relief mais aussi les variations colorimétriques liées à la différence entre un éclairage naturel et un éclairage artificiel. Pour ces différentes raisons, une systématisation de la prise de vue a été mise en place depuis plusieurs années, ayant pour but d’offrir au chercheur une documentation visuelle exhaustive, comprenant des vues générales à plusieurs échelles et des vues détaillées.
Dans un second temps, les équipes du CESCM assurent l’indexation de l’image ou du groupe d’images. À partir de recherches dédiées et d’une validation collective, l’information associée à l’image est intégrée dans la base de données. Dans tous les cas le vocabulaire utilisé est issu du thésaurus produit par « Groupe Image » du GAHOM (Groupe d’Anthropologie Historique de l’Occident Médiéval) [10]. L’objectif majeur de cette indexation est de fournir au chercheur ou à tout autre utilisateur un instrument de recherche documentaire, ce qui sous-tend : sans analyse du contenu.
Quels outils pour l’historien de l’art ?
Face à l’image médiévale, quelle qu’en soit la nature ou le support, la démarche de l’historien de l’art porte à la fois sur sa dimension matérielle, ses aspects formels et son iconographie.La principale différence existant entre les bases « Romane » et « Peinture » réside dans leur adaptation aux approches monographiques et/ou formelles d’une part et à l’analyse iconographique d’autre part. Pour répondre aux besoins des chercheurs, il était en effet nécessaire de développer dans un premier temps deux bases complémentaires. À très court terme toutefois, cette analyse discriminante permettra de concevoir une base unique et donner la possibilité à l’utilisateur de choisir entre une requête monographique, une requête iconographique ou une combinaison des deux5.
Dans la pratique de la recherche en histoire de l’art, les volets formel et iconographique ne peuvent pas être radicalement dissociés car ils sont parfaitement complémentaires, participant toujours, à des degrés divers, à la connaissance de l’œuvre, à sa datation, à l’évaluation de sa place dans un contexte artistique et culturel donné, etc. D’un autre côté, les analyses formelle et iconographique mobilisent souvent des outils différents et peuvent parfois déboucher sur des conclusions contrastées.

L’exemple des peintures de Sant’Angelo in Formis (figure 1) est à ce titre éminemment éclairant puisque, du point de vue de la forme, elles trahissent une étroite dépendance par rapport au courant pictural byzantin promu par l’abbé Didier, alors que du point de vue de l’iconographie, elles reflètent souvent un profond attachement du concepteur aux modèles occidentaux [22]. À l’inverse, l’ancrage d’une œuvre dans le substrat artistique local peut déterminer non seulement ses inflexions formelles mais aussi certains choix iconographiques. C’est ainsi qu’en Catalogne par exemple, des peintres appartenant à des ateliers différents mais inscrits dans un milieu artistique relativement homogène ont employé avec une récurrence exceptionnelle des thèmes ou des compositions communes [1].
L’historien de l’art se doit par conséquent de multiplier les passerelles entre les approches formelle et iconographique. Christian Davy [11] a parfaitement montré l’intérêt d’une subdivision rigoureuse du propos et d’un approfondissement des différents aspects de l’œuvre peinte : histoire, contexte architectural, iconographie, épigraphie, style, composition, fonds de scène, décors d’architecture, visage et corps, drapés…
L’indexation est en mesure de rendre compte de l’essentiel des composantes iconographiques de l’image. L’analyse a parfois suggéré que certaines composantes apparemment secondaires, comme le décor, les attitudes, les vêtements, etc., pouvaient être chargées d’un contenu sémantique non négligeable [4, 5, 6], mais l’indexeur ne peut raisonnablement pas répertorier tous ces détails, au risque de perdre un temps considérable et d’alourdir à l’excès les fiches analytiques. De plus, l’indexation textuelle des composantes formelles de l’image ne peut qu’être limitée du point de vue quantitatif, et ne peut en conséquence pas faire état de la composition, des attitudes, des gestes, des plis, des détails anatomiques, des rehauts lumineux… Ces limites sont inhérentes à l’indexation textuelle fondée sur un thésaurus de descripteurs nécessairement réduit face aux possibilités graphiques.
C’est en ce sens que le développement d’un outil capable d’effectuer des comparaisons entre composantes graphiques ou de rechercher des composantes similaires dans une base d’images peut apporter une aide au chercheur en histoire de l’art. L’association d’une requête textuelle et d’une recherche graphique à partir du contenu pictural offre alors les moyens de combiner recherche iconographique et formelle.
Un système d’indexation par le contenu pictural
L’avènement des technologies de l’information a popularisé les moteurs d’indexation textuels. Dans ces modes, le système de recherche utilise des mots et des expressions comme pointeurs vers les phrases, les paragraphes et les pages des documents. De manière similaire, indexer des images revient à extraire des attributs caractéristiques du contenu d’une image puis à exploiter ces caractéristiques de la même manière que le sont des mots pour un document textuel.
L’intérêt d’une recherche par le contenu graphique est de pouvoir rechercher des images entières ou des portions d’images sans avoir à nommer ou identifier le contenu. Ce qui les différencie des systèmes de gestion électronique de documents ou des moteurs de recherche (Google, Yahoo…), pour lesquels un module de recherche d’images existe mais travaille à partir des mots associés à l’image (titre, description, texte environnant, contenu du document). Mais plus précisément dans le cadre de l’aide à l’expertise en histoire de l’art, un tel outil permet de résoudre la distanciation nécessaire entre l’abstraction textuelle et la complétude descriptive : la pertinence d’un système d’indexation textuel décroît avec la complétude descriptive.
Principe
L’indexation de bases d’images par le contenu (CBIR en anglais pour Content Based Image Retrieval) repose sur un schéma en deux temps qui nécessite dans une première phase l’extraction de caractéristiques pertinentes et robustes. Ces caractéristiques peuvent être globales à l’image ou locales à certaines parties de l’image. Cette première phase est qualifiée de hors-ligne car établie lors de la conception du système. La seconde partie correspond à la phase de recherche proprement dite, elle nécessite la mise en place de métriques de comparaison entre un ensemble de caractéristiques issues de la requête et les caractéristiques des images sélectionnées dans la base d’images. Cette phase est dite en ligne, car estimée en temps réel durant la consultation de l’utilisateur (figure 2).

Dans une telle problématique, les attributs correspondent à des descriptions dites bas-niveau6, relatives à la forme, la texture, la couleur de l’ensemble de l’image (requête globale) ou de différentes régions constituant une image (requête partielle). La complexité réside dans le choix de ces attributs. En effet si, dans le cadre d’une indexation textuelle, les lettres et assemblages de lettres sont porteurs d’une sémantique évidente mais liée à la langue d’utilisation, le contenu des images peut être porteur d’une sémantique très différente selon l’observateur (grand public, amateur ou spécialiste) et de plus indépendante de la langue de l’utilisateur. Malheureusement les difficultés scientifiques résident d’une part dans l’extraction d’informations invariantes aux variations d’éclairage, d’échelle et d’orientation ; variations dont le cerveau humain fait largement abstraction. Mais surtout la difficulté scientifique réside dans la recomposition de l’information haut-niveau incluse dans l’image et décrite par la sémantique7 associée. Cette recomposition résulte de deux opérations, une première phase de décomposition (segmentation) et une phase de raffinement de la décomposition.
Que ce soit pour l’image entière ou pour les régions issues de la segmentation finale, un ensemble de paramètres (attributs) permet de caractériser le contenu. Le choix de ces attributs est dépendant des invariances souhaitées.
Dans le cadre particulier des images médiévales, il est nécessaire de pouvoir combiner les éléments sémantiques issus des index textuels avec l’organisation de l’image. Le choix d’une structure informatique adaptée à cette question est évidemment un problème important, puisque la structure devra supporter les problèmes de mesure de ressemblance/dissemblance.
La première difficulté d’un système d’indexation est donc de déterminer un ensemble de paramètres caractéristiques, le plus possible invariants aux variations d’échelle, de direction, d’éclairage (figure 2 : l’espace de représentation). Il s’agit ensuite d’agencer ces paramètres dans une structure de représentation qui pourra prendre en compte la topologie existant entre les objets. Cette structure correspond à la signature de l’image. Il restera alors à définir les métriques qui permettront de comparer efficacement deux signatures entre elles.
Quel rôle peut jouer un système d’indexation par le contenu en association avec un système d’indexation textuel ? En dehors du simple fait de permettre de retrouver des éléments graphiquement similaires (en partie ou en totalité), il est possible de considérer un système d’indexation d’images par le contenu comme une mémoire de cas. Cette mémoire est bien évidemment une mémoire d’images mais aussi une mémoire de résultats de traitement et d’expertises. Ainsi, c’est en exploitant les fonctionnalités d’un système d’indexation par le contenu pixellaire que le SIC s’est attaché à la résolution du problème d’aide au diagnostic pour le cancer de la peau ou encore à celui de la détection de défauts dans des pièces métalliques.
Par exemple, dans l’application dermatologique, l’idée fondamentale a été de constituer des bases de référence à partir des pratiques usuelles des médecins qui produisaient systématiquement des diapositives des lésions de leurs patients. Ces diapositives présentent toujours les mêmes caractéristiques : une lésion isolée au centre de la photo. Il est facile de numériser ces diapositives même si elles présentent un certain nombre d’imperfections et l’enjeu était alors de leur associer des paramètres et métriques en relation avec les règles basiques de diagnostic puis de fournir aux spécialistes une interface conviviale et paramétrable. Cette interface permet de confronter un cas de lésion suspect à une base importante de cas bénins et malins, validés par biopsie. Le système d’indexation fournit en retour les images les plus proches de l’image soumise avec l’expertise médicale associée (bénin ou type de malignité). Le médecin peut alors prendre une décision d’excision en prenant en compte cette aide à la décision. Le système ne le remplace pas mais lui offre la mémoire et l’expertise de plusieurs spécialistes pour l’assister.
Extraire les composantes graphiques
Mettre en place un système d’indexation par le contenu graphique nécessite trois phases : une phase de segmentation pour répartir le contenu pixellique en zones visuellement homogènes, une phase descriptive pour associer chaque zone à un ensemble de descripteurs et enfin une phase de mesure de différences. Nous allons présenter successivement les éléments de référence de ces trois phases.
Le problème de la segmentation
Définition
La segmentation est une opération qui a pour objectif l’établissement d’une partition de l’image en régions. Cette partition est telle que deux régions contiguës soient différentes au sens des attributs choisis pour cette opération (couleur, texture…) ou qu’il existe une rupture suffisante entre ces deux régions (présence d’un contour) [9, 7].
Limites
La segmentation est un prétraitement dans un système de traitement d’images. La partition de l’image obtenue vise souvent à se rapprocher de la partition souhaitée par l’utilisateur (sa vision de la composition de l’image), mais ce n’est qu’aux termes de traitements additionnels et de l’intégration de connaissances issues des experts qu’une telle convergence est possible [20, 14].
Permettre à l’expert d’exploiter un outil de traitement d’images impose de mettre en place une chaîne d’opérateurs faisant converger des partitions vers une carte de régions se confondant avec l’organisation sémantique du contenu de l’image. Ce qui présuppose selon le schéma de Fayyad, une exploitation en 5 étapes (figure 3) : l’(les) acquisition(s), les prétraitements d’amélioration, le partitionnement, le calcul d’attributs et le raffinement. Dans ce schéma, chaque étage est bouclé et l’ensemble peut être repris en fonction du résultat final.
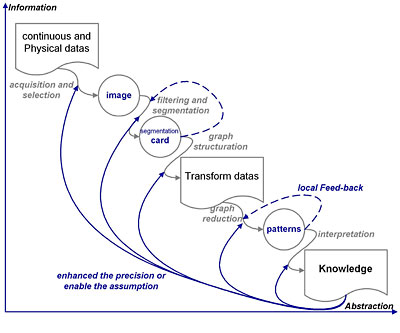
Les contraintes de l’outil de segmentation
Dans le cadre des images médiévales, la taille moyenne des images et la résolution génèrent des images de grande taille (supérieure à 9 millions de pixels), images pour lesquelles les contours sont souvent faiblement marqués et les dégradations génèrent des variations de textures (variation de l’aspect coloré). Les techniques de traitement à mettre en place doivent par conséquent être de type multi-résolution, intégrer un aspect texture couleur qui tienne compte du rendu perceptuel.
La dimension chromatique est évidemment extrêmement importante dans ces images et impose l’utilisation de traitements adaptés. Julien Dombre [13] a montré que grâce à l’utilisation d’un protocole photographique strict pour l’acquisition et la numérisation, il est possible d’effectuer les traitements dans des espaces classiques (RGB, TLS…).
Permettre à l’ordinateur de lire l’image comme le fait l’expert nécessite de raffiner les cartes de segmentation issues de la phase de prétraitement. Dans un premier temps sont présentés les méthodes de partitionnement de l’image puis les éléments de raffinement de ces cartes. Le raffinement nécessite de travailler sur le contenu des régions, ce qui est effectué au travers de descripteurs qui seront explicités dans un second temps.
La catégorisation des méthodes de segmentation
Bien que la décomposition des techniques soit plus complexe que cela, dans un premier temps les outils de segmentation peuvent être scindés en trois catégories :
Les méthodes par recherche de discontinuité : l’objet de cette classe de méthode est d’extraire les contours de l’image et toutes les discontinuités, puis dans une seconde phase de reconstruire des régions à partir de ces informations. Ce qui nécessite bien souvent d’appliquer des règles et des modèles pour fermer les contours et reconstruire des régions.
Les méthodes de classification pixellaire : l’idée générale de ces approches est de considérer que l’image a été créée avec un ensemble de couleur qui sont représentatives des régions recherchées de l’image. L’exploitation d’outils classiques de l’analyse statistique et de la classification permet de réduire la complexité de la distribution tridimensionnelle. Plusieurs méthodes existent soit par classification des trois histogrammes unidimensionnels (un par plan couleur), soit par classification de l’histogramme tridimensionnel ou plus simplement à partir de méthodes de regroupement par paquets (clustering). Les méthodes les plus populaires sont celles exploitant des techniques de type octree optimisée (découpe successive des voxels pavant l’espace 3D des couleurs), ou des méthodes de type Fuzzy C-mean [18, 17].

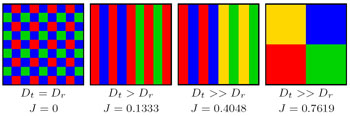
Comme le montre la figure 48, ce type de méthode ne peut apporter une grande aide dans la résolution du problème de la segmentation des images de peintures murales. Ceci pour deux raisons : la première tient aux fortes dégradations des supports qui génèrent des variations de teintes et de saturation dans les couleurs (820 000 couleurs uniques dans l’image du lion ailé de saint Marc), la seconde propre à ces techniques tient dans le fait que proximité couleur n’implique pas forcément proximité spatiale. Les développements de ces méthodes n’ont permis de résoudre qu’une partie de ces difficultés, mais permettent d’apporter des réponses intéressantes dans le cas des images multimédia (plus de couleurs, plus de contraste…).
En revanche, les méthodes de cette catégorie font partie des éléments nécessaires en prétraitement au même titre que les techniques de filtrages et de changement d’espace. Dans ce cadre, elles permettent de réduire la complexité de l’image.
Les méthodes par recherche de zones homogènes : ces techniques œuvrent dans l’espace des pixels et non plus dans l’espace des couleurs. Elles cherchent à associer des pixels se ressemblant (méthodes ascendantes de regroupement) ou à décomposer l’image en zones homogènes (méthodes descendantes de division). Dans ce second cas, les méthodes classiques partagent l’image selon différents schémas (quadtree, triangulation…) pour ensuite appliquer un schéma de fusion pour les régions voisines et similaires en contenu. L’enjeu est que par cette alternance de division de régions hétérogènes et de fusion de régions similaires les formes utilisées correspondent au plus près en taille et en nombre à l’organisation de l’image.
Les méthodes du premier cas évaluent pour chaque pixel la distribution des couleurs de pixel dans le voisinage ou toute autre statistique équivalente (information de type texture par exemple). Les pixels sont ensuite agglomérés selon ces statistiques. Différentes stratégies d’agglomération discriminent les méthodes (lignes de partage des eaux, hiérarchique, réduction de graphe…).
L’algorithme proposé par Deng [12] et utilisé dans notre application appartient à cette classe de méthodes : un critère (![]() ) est déterminé pour chaque pixel. L’importance du critère est directement proportionnelle à l’hétérogénéité de l’environnement du pixel.
) est déterminé pour chaque pixel. L’importance du critère est directement proportionnelle à l’hétérogénéité de l’environnement du pixel.
L’aspect multi-échelle dans la segmentation
La composition au sens sémantique d’une image de type multimedia ou plus spécifiquement d’une peinture murale s’appuie sur une organisation d’objets de premier plan et plans secondaires, eux-mêmes caractérisés par plusieurs niveaux de détails. Une approche travaillant au travers des échelles cherche à exploiter cette construction pour mieux gérer la phase de segmentation. Deux types d’approche existent, soit des techniques dites descendantes (ou « coarse to fine »), c’est-à-dire produisant une segmentation grossière aux premières échelles puis affinant celle-ci par l’exploitation de résolutions de plus en plus fines. Soit des techniques ascendantes (« bottom-up ») qui partent des échelles de haute résolution et produisent des cartes de segmentation très précises mais trop complexes. Puis en allant vers des échelles de résolution plus grossière ces méthodes cherchent à réduire cette complexité. La première catégorie vise à optimiser les temps de traitement pour la segmentation d’images de grande taille, alors que la seconde vise à produire une segmentation précise et cohérente, respectant les contours et ruptures de textures. C’est cette dernière voie qui est nécessaire pour nos traitements, car elle permet d’obtenir facilement les relations d’inclusions qui correspondent à la construction de l’image en un ensemble d’objets complexes.

Structurer et représenter une carte de segmentation
La carte de segmentation représente une partition de l’espace pixel en une somme de régions. Même si cela est souhaité, la partition produite ne coïncide que rarement avec les découpages sémantiques produits par l’expert ou simplement l’utilisateur. L’objet de la phase d’interprétation est de faire converger la partition vers cette découpe en objets connus. Cette phase de post-traitement nécessite de prendre en compte la gestion des différents niveaux de détails et l’organisation spatiale des objets entre eux. La structure la plus adaptée à cette manipulation est une carte topologique, qui seule permet de maintenir toutes les informations de voisinage et de localisation des objets entre eux dans une image. L’adaptation au cas multi-échelle a été proposée par Brun et Kropasch. Néanmoins aucune métrique n’existant pour ce type de représentation9, une représentation par graphes d’adjacences est utilisée.
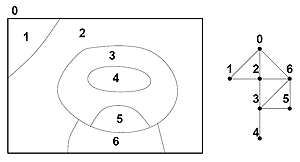
La prise en compte de l’aspect multi-résolution est traditionnellement attachée directement à l’outil de segmentation dans le cadre des méthodes ascendantes ou descendantes. Une telle approche en limite l’exploitation. Les travaux en modélisation géométrique ont montré l’intérêt de travailler sur des structures de représentation plutôt que directement sur la représentation. Certains travaux proposent même de changer la nature de l’espace de représentation pour choisir celle la plus adaptée au traitement (Nogemo : cartésien -> discret -> topologique).
La structure de données recherchée est l’aboutissement de la phase de prétraitement et de l’intégration de modèles de segmentation, elle doit donc être la plus proche possible de la phase d’interprétation et permettre de redescendre aisément à l’information pixel.
Parmi les représentations possibles, les plus courantes sont conçues autour de pyramides régulières ou de pyramides de graphes (pyramides irrégulières). Dans les deux cas, la construction est liée à une technique de segmentation de type montante (du pixel vers l’image) où chaque région d’un niveau donné est fusionnée avec celles qui lui sont visuellement proches et connexes. Dans la construction de ce type de représentation, le protocole de fusion peut s’arrêter lorsqu’un nombre préétabli de régions principales a été trouvé, suivant un critère de qualité de segmentation par exemple. Les limites d’une telle approche pour les images de peintures murales résident dans le fait que les critères de segmentation ont été écrits pour des images de type multimédia de complexité moins importante.
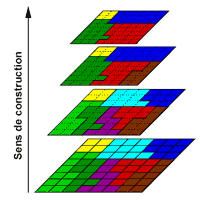
En conclusion, la taille et la résolution des images impose plutôt de disposer d’une structure partant de l’image et allant vers le pixel (description descendante). Le nombre de niveaux de description peut être alors paramétré en fonction de la précision souhaitée ou de la taille des éléments minimum que doit décrire la représentation. Sous cet angle, ce sont les objectifs de la phase d’interprétation qui viennent définir le paramétrage de la segmentation.
La représentation des segmentations obtenues la plus souple est une structuration de type graphe pour chaque niveau de résolution (aspect spatial), pour lequel chaque nœud se décompose lui-même en un graphe (aspect multi-résolution).
Pour un niveau de segmentation donné, l’image ![]() fournit une partition
fournit une partition ![]() avec
avec
![]() l’ensemble des niveaux de segmentation. La décomposition multi-résolution est cohérente, si et seulement si chaque région du niveau
l’ensemble des niveaux de segmentation. La décomposition multi-résolution est cohérente, si et seulement si chaque région du niveau ![]() est incluse dans une région unique du niveau
est incluse dans une région unique du niveau ![]() . Cette condition permet l’intégration de la notion de composition de régions pour former un objet complexe.
. Cette condition permet l’intégration de la notion de composition de régions pour former un objet complexe.
A chaque niveau ![]() de la segmentation, un graphe d’adjacence est construit pour représenter la partition. Chaque région est associée à un nœud du graphe
de la segmentation, un graphe d’adjacence est construit pour représenter la partition. Chaque région est associée à un nœud du graphe ![]() et un ensemble d’arête
et un ensemble d’arête ![]() décrit les relations de voisinage.
décrit les relations de voisinage.
où
L’aspect multi-résolution et combinaison de régions pour former des ensembles plus complexes est pris en compte dans l’intégration d’arêtes de composition entre une région du graphe au niveau ![]() et les
et les ![]() régions du niveau
régions du niveau ![]() . Ces relations sont stockées dans un second ensemble d’arêtes :
. Ces relations sont stockées dans un second ensemble d’arêtes :
avec
Le graphe pyramidal d’une image est alors construit à partir de la série
![]() et se compose de :
et se compose de :
Le choix du nombre de niveaux de décomposition ![]() permet intrinsèquement de limiter la complexité de la description en fonction de l’objet à étudier. Ce choix tient également compte de la réduction de la qualité de l’information due à la prise de vue. Des structures de petite taille se retrouveront décrites sur quelques dizaines de pixels à un niveau de détail donné.
permet intrinsèquement de limiter la complexité de la description en fonction de l’objet à étudier. Ce choix tient également compte de la réduction de la qualité de l’information due à la prise de vue. Des structures de petite taille se retrouveront décrites sur quelques dizaines de pixels à un niveau de détail donné.

Une des particularités de la photothèque du CESCM est de disposer d’images prises à différents grossissements, ce qui permet d’avoir dans la même base des vues générales et des vues de détails. Moyennant quelques précautions de recalage, la structure produite peut tout à fait profiter de l’accroissement de résolution pour affiner la composition des objets (cas de la fusion d’information de grossissement plus important). Les précautions à prendre résultent du maintien de la règle de cohérence de la segmentation pour que les régions concernées soient bien identiques dans les deux images ; la précision du pixel n’est cependant pas nécessaire. L’intérêt est alors d’avoir une structure complète de l’objet décrit dans plusieurs images et qui pour chacune d’entre elles correspond au même objet sémantique (continuité de la sémantique selon la prise de vue). La structure devient donc complète et exacte (par les différents niveaux de détails) et permet dès lors de travailler indépendamment du problème de l’échelle d’analyse (grossissement). L’intérêt de la fusion de cartes de segmentation est également d’améliorer la prise d’informations dans chaque région. Toute information établie dans des zones de petite taille est entachée d’imprécision, alors que l’accroissement de résolution optique va permettre de résoudre ce problème.
Dernier problème délicat à gérer dans ce cadre de fusion de carte de segmentation, celui des contours ou traits épais. Typiquement, les images médiévales présentent deux types de traits : ceux amplifiant le contour de zones uniformes et ceux esquissant un détail dans le dessin d’un objet volumique. Pour des représentations rapprochées chacun de ces traits se trouve être considéré comme une région à part entière.
Caractériser le contenu d’une région
Partitionner une image en régions nécessite un ou plusieurs algorithmes de gestion de la procédure de division ou de regroupement, mais aussi des informations de base sur lesquelles vont porter les décisions de fusion de régions ou de partage d’une région en deux parties. Le choix de ce type d’informations influe autant que le choix de l’algorithme dans la décision finale. Les descripteurs utilisés doivent servir à la fois pour la segmentation et pour la caractérisation du contenu nécessaire à la phase de recherche et comparaison des images.
Techniquement, les attributs utilisés pour la phase de segmentation utilisent des descripteurs exploitant l’information couleur et/ou texture, alors que ceux rajoutés pour la phase de caractérisation peuvent exploiter en plus des informations de forme et de contour.
L’information couleur est prépondérante dans le cadre des images médiévales pour la perception de la construction picturale de l’image. À cette information s’ajoute la définition de l’aspect texture en traitement d’images qui permet de prendre en compte les variations locales de l’image (luminance et/ou chromatique). La difficulté liée au positionnement de ces méthodes réside dans les variations importantes du support mural de l’œuvre qui introduit des modifications de même échelle dans la couleur et dans l’aspect de surface. Ces altérations sont par conséquent fortement perçues par le système d’acquisition et induisent des difficultés importantes pour faire converger la carte de segmentation vers le contenu pictural (au sens sémantique). Les résultats de segmentation de la figure 6 illustrent ce problème dans le partitionnement avec soit un grand nombre de petites régions au contenu visuellement identique (le fond gris), soit la construction de grandes régions à contenu visuellement différent (image de gauche).
Construire une métrique de comparaison
Quels sont les objectifs de la mesure de comparaison de deux images ?
Plusieurs niveaux d’objectifs peuvent être assignés à la mesure de ressemblance. Le premier d’entre eux correspond à celui de la ressemblance exacte. Ce cadre correspond par exemple à celui de l’authentification des monnaies et contrefaçons. Le deuxième correspond à une mesure de ressemblance avec dérive d’une des composantes, couleur par exemple pour le contrôle qualité en imprimerie. Le troisième intègre une mesure de ressemblance partielle entre les deux images. Dans ce dernier cas, la mesure cherche à établir la proportion de ressemblance entre les deux images.
Ce dernier cas est bien évidemment le plus complexe, car il nécessite deux phases séparées, l’une pour apparier10 les deux structures et estimer les manques potentiels dans cet appariement ; l’autre phase pour mesurer la ressemblance entre les différentes parties de la structure.
La définition de la charte d’objectifs est double dans notre problématique. Nous attendons dans un premier temps que notre système puisse aider l’expert dans son analyse discriminatoire, c’est-à-dire qu’il mesure des différences entre parties d’images. Ce cadre est plus proche du second niveau possible d’exploitation des métriques de comparaison, puisque de l’ordonnancement produit peut naître une interprétation.
Cependant pour être d’une aide suffisante pour l’expert, cette phase nécessite de pouvoir identifier simplement des zones précises de l’image (mains, tête, drapés…). Ce qui implique de disposer de segmentations de référence isolant et identifiant ces zones ainsi que d’une métrique de comparaison capable d’estimer la probabilité de présence d’une telle zone dans une image. Les objectifs de la métrique de comparaison sont donc bien du troisième niveau d’objectif. Ce dernier cadre correspond également au besoin du système de segmentation, qui attend de trouver dans la base des images ressemblant partiellement à celle pour laquelle il veut trouver la meilleure partition.
Construire une métrique entre descripteurs d’images ?
Si nous considérons deux régions issues de deux images différentes, comment comparer ces deux régions au travers d’une métrique ? Les éléments traditionnels du traitement d’images nous fournissent différents attributs traitant de la couleur, de la texture ou de la forme pour décrire ces régions.
Si nous limitons le propos à celui de la couleur, nous pouvons par exemple décrire la ressemblance des deux régions selon leur histogramme couleur. Pour une image
![]() quantifiée dans un espace couleur réduit à n classes couleurs
quantifiée dans un espace couleur réduit à n classes couleurs
![]() , l’histogramme couleur H est un vecteur à
, l’histogramme couleur H est un vecteur à ![]() composantes :
composantes :
![]() pour lequel
pour lequel ![]() représente le nombre de pixels de couleur
représente le nombre de pixels de couleur ![]() dans l’image A. On a en particulier
dans l’image A. On a en particulier
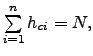 où
où ![]() est le nombre de pixels de l’image.
est le nombre de pixels de l’image.
La dissimilarité entre deux images
![]() et
et
![]() peut alors s’exprimer selon ces vecteurs couleur via toutes les distances géométriques classiques
peut alors s’exprimer selon ces vecteurs couleur via toutes les distances géométriques classiques
![]() et
et
![]() respectives :
respectives :
![]() .
.
Le choix de la fonction de mesure doit se faire de façon à respecter les propriétés classiques des distances :
- positivité : d(X,Y) ![]() 0,
0,
- identité : d(X,X) = 0,
- symétrie : d(X,Y) = d(Y,X),
- inégalité triangulaire : d(X,Y) ![]() d(X,Z) + d(Z,Y).
d(X,Z) + d(Z,Y).
Parmi les modalités les plus connues, nous retrouvons les normes de type ![]() et
et ![]() , qui appartiennent au cadre classique des distances de Minkowski
, qui appartiennent au cadre classique des distances de Minkowski ![]() .
.
Norme ![]() :
:
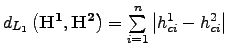 .
.
Norme ![]() :
:
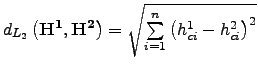
Norme
![]() :
:
![]() .
.
Norme ![]() :
:
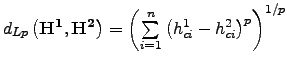
Dans la formulation de la norme ![]() , nous retrouvons la classique distance euclidienne, alors que dans la norme
, nous retrouvons la classique distance euclidienne, alors que dans la norme
![]() la distance conservée est le plus grand écart mesuré sur l’ensemble des deux vecteurs. A priori, ce type de métrique pourrait être adapté, mais cela serait oublier l’aspect perceptuel de ce type de mesure. La figure 10 permet de mieux comprendre le phénomène. Dans le premier cas (côté gauche), nous trouvons la même image dont les conditions d’illumination ont été modifiées ; dans le second cas, nous trouvons deux images différentes. Quelle que soit la métrique utilisée, le second cas est considéré comme étant toujours plus ressemblant !
la distance conservée est le plus grand écart mesuré sur l’ensemble des deux vecteurs. A priori, ce type de métrique pourrait être adapté, mais cela serait oublier l’aspect perceptuel de ce type de mesure. La figure 10 permet de mieux comprendre le phénomène. Dans le premier cas (côté gauche), nous trouvons la même image dont les conditions d’illumination ont été modifiées ; dans le second cas, nous trouvons deux images différentes. Quelle que soit la métrique utilisée, le second cas est considéré comme étant toujours plus ressemblant !
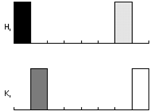
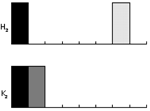
Sans étendre plus en avant le problème de la métrologie entre attributs, ce simple exemple permet de comprendre la complexité d’association entre un attribut et une métrique d’évaluation, puisque cette association doit dépendre des capacités du système visuel humain pour appréhender ces variations.
Estimer la ressemblance entre deux structures ?
La structure d’une carte de régions est captée par un graphe, actuellement un graphe d’adjacence. Cette structure de données associe à chaque arête (c’est-à-dire une relation de voisinage) et à chaque sommet (c’est-à-dire une région) un certain nombre d’attributs. La mesure de ressemblance entre deux peintures doit par conséquent intégrer deux étages d’estimation des dissemblances / ressemblances. Le premier correspond à la mesure de similarité des structures, alors que le second plus en profondeur inclut l’estimation des ressemblances en terme de couleur/forme/texture. Pour le premier étage, la mesure de ressemblance intègre un cumul de ressemblance entre les nœuds et les arêtes deux à deux (initial vs requête). L’estimation locale utilise une formulation intégrant une fonction pondérant l’effet des attributs locaux. Les méthodes permettant ce type de mesure rentrent dans le cadre des algorithmes d’appariement (« graph-matching algorithm »).
Appariement exact
La formalisation du problème s’effectue en considérant un grapheAppariement inexact
Cependant, le cadre qui nous intéresse est plus vaste que celui de la recherche d’un isomorphisme (appariement exact des deux graphes), il s’apparente à la recherche du meilleur appariement partiel (inexact). Ne serait-ce que par la présence des occlusions, des dégradations partielles ou plus simplement par la variabilité humaine, il est inimaginable d’espérer trouver deux peintures exactement semblables dans leurs structures. En revanche, retrouver des portions de graphes (c’est-à-dire de morceaux de fresques) similaires entre deux peintures a un sens pour le travail de l’historien de l’art. Parmi les quelques méthodes existantes, celles autorisant l’appariement de sous-graphes (id. portions d’images) correspondent aux besoins de l’application [15, 21].
La formulation proposée par Gold cherche à minimiser une fonction exprimant la différence entre un graphe G, comportant
![]() nœuds, et un graphe
nœuds, et un graphe
![]() composé de
composé de
![]() nœuds. Il s’agit dans ce cas de trouver la meilleure matrice de correspondance
nœuds. Il s’agit dans ce cas de trouver la meilleure matrice de correspondance
![]() entre les nœuds de
entre les nœuds de
![]() et ceux de
et ceux de
![]() . Cette matrice permettant de minimiser la fonction de coût :
. Cette matrice permettant de minimiser la fonction de coût :
![]() .
.
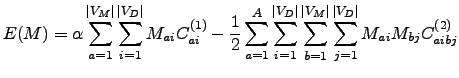 (3)
(3)
Dans cette formulation,
![]() correspond à une mesure de similarité entre les sommets
correspond à une mesure de similarité entre les sommets
![]() de
de ![]() et
et
![]() de
de
![]() :
:
![]() .
La mesure de ressemblance entre deux nœuds
.
La mesure de ressemblance entre deux nœuds
![]() nécessite l’utilisation d’une fonction de mélange entre les différents attributs décrivant les régions (c’est-à-dire les nœuds). La première partie de la fonction de coût
nécessite l’utilisation d’une fonction de mélange entre les différents attributs décrivant les régions (c’est-à-dire les nœuds). La première partie de la fonction de coût
![]() estime donc pour une matrice de mise en correspondance
estime donc pour une matrice de mise en correspondance
![]() donnée, la ressemblance globale des paires de nœuds.
donnée, la ressemblance globale des paires de nœuds.
De la même façon,
![]() correspond à une mesure de ressemblance entre l’arête liant la paire de sommet
correspond à une mesure de ressemblance entre l’arête liant la paire de sommet
![]() et la paire
et la paire
![]() . Usuellement, ce terme est peu employé et prend la valeur
. Usuellement, ce terme est peu employé et prend la valeur
![]() lorsqu’il existe une arête entre les nœuds
lorsqu’il existe une arête entre les nœuds
![]() et que celle-ci a un équivalent entre les nœuds
et que celle-ci a un équivalent entre les nœuds
![]() . Dans le cas contraire,
. Dans le cas contraire,
![]() .
Cette seconde partie de la formulation vient donc pondérer le résultat précédent par le maintien des relations entre les nœuds considérés.
.
Cette seconde partie de la formulation vient donc pondérer le résultat précédent par le maintien des relations entre les nœuds considérés.
Le développement de la fonction ![]() par l’intermédiaire d’une décomposition en série de Taylor permet la résolution de ce problème par une technique de programmation linéaire.
par l’intermédiaire d’une décomposition en série de Taylor permet la résolution de ce problème par une technique de programmation linéaire.
L’intégration d’une mesure pluri-attribut pour l’estimation de ressemblance entre deux régions nécessite soit de mélanger de façon aveugle les attributs en dérivant une des normes vues précédemment, soit d’utiliser une approche de type fusion, qui impose d’établir par une étape d’apprentissage le poids de chaque attribut dans la phase de comparaison [16], soit toujours après une phase d’apprentissage d’établir une stratégie de type arbre de décision qui permet d’adopter un comportement non linéaire du système de métrologie.
Deux exemples
Un premier exemple : la recherche de provenance
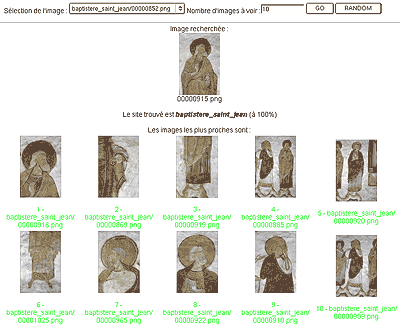
Pour quantifier l’intérêt de ce type d’approche pour le domaine, nous avons mis en œuvre deux exemples de validation [13]. La première a pour objet de retrouver la provenance d’une peinture murale. Cette démonstration ne correspond à aucune application particulière mais permet juste de montrer les capacités de description de chaque image. En soumettant une image au système de requête (figure 11, image en haut au centre), les images les plus proches qui sont fournies appartiennent au même site et correspondent à des vues de détail ou des plans d’ensemble (figure 11, suite d’images classées par ordre de ressemblance de façon decroissante et limitée à 10 voisins). Bien évidemment, suivant le taux de dégradation ou la représentativité de l’image requête, les résultats varient (83 % en moyenne de bonne classification, 7 % d’erreur et 10 % de non décision). La validation a eu lieu sur 463 images avec une vingtaine d’images par site en moyenne.
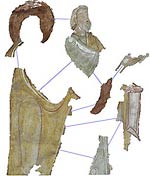
Les mains : une première association entre iconographie et étude des formes
Le second exemple correspond à un travail en cours. Pour amorcer cette recherche, le CESCM a choisi de travailler sur la forme de la main, d’une part parce qu’elle constitue l’une des caractéristiques formelles signifiantes de la peinture romane, d’autre part parce que le logiciel est susceptible de l’identifier plus facilement qu’une autre partie de l’anatomie ou toute autre composante de l’œuvre. Au départ d’une trentaine de gros plans de mains issues de sites différents, nous avons établi une typologie relativement simple, reposant sur la position de la main et les détails. La typologie relative à la position de la main sert essentiellement au logiciel appelé à reconnaître cette partie du corps, quel que soit son aspect général : ouverte/fermée ; paume/dos ; deux doigts tendus ; pouce détaché des autres doigts, etc.

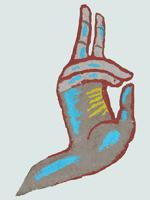
La typologie relative aux détails vise au contraire à dégager des procédés spécifiques à chaque peintre ou atelier. Elle concerne d’une part les traits sombres, d’autre part les rehauts clairs. Les traits peuvent définir les éminences thénar et hypothénar11, les doigts «tripartites» autrement dit ceux dont les phalanges ont été séparées par un trait perpendiculaire, les ongles et enfin les lignes parallèles parcourant la paume, perpendiculairement aux doigts. Quant aux rehauts clairs, ils peuvent signaler le relief des éminences thénar et hypothénar, les phalanges et enfin les ongles.
L’observation minutieuse de ces détails était indispensable pour la phase d’apprentissage nécessaire au logiciel. Mais du seul point de vue de l’historien de l’art, cette observation a déjà permis de confirmer l’intérêt d’une analyse des détails. La comparaison d’une trentaine de mains a de fait révélé des différences notables entre les sites, mais aussi à l’intérieur d’un même ensemble. Nous avons ainsi observé qu’au baptistère Saint-Jean de Poitiers, le traitement était différent selon que la main appartenait à un apôtre ou à une figure divine. La combinaison des lignes parallèles de la main avec les traits et les rehauts clairs définissant les éminences thénar et hypothénar ne se retrouve en effet que sur la main de Dieu inscrite dans un médaillon et sur celles du Christ de l’Ascension. Il apparaît très clairement que dans cet exemple, les différences formelles n’impliquent pas une attribution des peintures à des peintres différents, mais plus simplement une hiérarchisation des figures par le biais de leur traitement.
La phase d’apprentissage a nécessité l’utilisation d’un logiciel de retouche d’images pour labelliser à l’aide d’un code couleur les différentes régions de la main. Pour faciliter la reconnaissance de ces détails par le logiciel, nous avons procédé à un travail d’accroissement des contrastes. En utilisant un logiciel de retouche d’images classique, l’équipe de la photothèque a attribué, arbitrairement, à chaque type de trait sombre ou de rehaut clair une couleur à la fois différente et contrastant avec les autres couleurs.
Perspectives
La recherche menée conjointement par le laboratoire SIC et le CESCM a pour objectif de développer des stratégies de lecture automatique d’images dans les bases de données de peintures murales. L’extension de ces travaux sur des documents hybrides alliant images, textes ou représentations symboliques est en cours d’étude (musicologie, parchemin, sculpture et architecture). Ce projet, amorcé il y a cinq ans, a nécessité dans un premier temps une définition des besoins de l’historien de l’art en la matière, autrement dit des objectifs d’une telle entreprise. Dans le même temps, un travail exploratoire a permis de dégager les problèmes scientifiques posés au traitement d’images.
Dans le domaine de l’iconographie, il est apparu très rapidement que l’indexation par le contenu pouvait difficilement élargir les informations fournies par l’indexation textuelle. Il se pourrait qu’une interrogation portant sur une image non identifiée aboutisse à des résultats auxquels le chercheur n’aurait pas songé et suggère en conséquence une hypothèse d’interprétation, mais ce cas de figure relève manifestement de l’exception. En revanche, l’outil informatique peut être d’une très grande utilité lorsque l’identification est compromise par l’état lacunaire ou la dégradation de la peinture. Par le recoupement avec des cas proches, au sens de différents descripteurs ou gammes d’informations, le système informatique propose des hypothèses à l’historien de l’art. Ces hypothèses ne sont nullement des solutions, seulement des cas semblables à partir desquels une nouvelle phase prospective peut être entamée.
Les possibilités offertes par l’indexation de l’image par le contenu sont toutefois beaucoup plus étendues dans le champ de la recherche formelle. Il convenait dès lors de définir les objectifs d’une telle recherche et les moyens nécessaires pour la mener à bien, en tenant compte de la diversité des points de vue et des méthodes. On peut avancer sans prendre beaucoup de risques que la recherche formelle vise avant tout à comprendre les spécificités stylistiques d’un peintre ou d’un atelier. Ces spécificités se dégagent à travers l’analyse de l’œuvre, ce qui suppose une caractérisation des nombreuses composantes formelles : structure, couleur, modelé, anatomie, drapé, etc. Dans un second temps, elle se dessine plus précisément à l’aune des œuvres contemporaines, par le biais de comparaisons. Parfois, ces comparaisons peuvent déboucher sur des attributions, des regroupements, voire un catalogue et une hypothèse de datation. Dans la peinture de la fin du Moyen Âge, l’affirmation des styles personnels permet de fonder les attributions sur des analogies substantielles, mais à l’époque romane, l’emploi de conventions largement répandues masque souvent les personnalités artistiques, si bien qu’il est extrêmement difficile d’attribuer deux œuvres au même peintre ou au même atelier. On observera d’ailleurs à ce sujet que même dans le domaine de l’art moderne, où les personnalités sont encore plus marquées, cet exercice, parfois qualifié d’ « attributionisme », suscite aujourd’hui une certaine perplexité et connaît en tout cas un réel ralentissement. Cette tendance est extrêmement troublante puisqu’à ses débuts, l’histoire de l’art médiéval s’était précisément inspirée de la méthode comparatiste adoptée par les modernistes.
Dans leur recherche formelle, les historiens de l’art roman font encore régulièrement de l’attribution et de la datation les objectifs ultimes de la recherche formelle, mais paradoxalement, ils ne mettent pas toujours en œuvre tous les ressorts fournis par la comparaison. Certes, le regard de l’historien de l’art, rompu à l’exercice de l’observation et de la comparaison, suffit parfois pour établir un rapprochement convaincant. Il n’en demeure pas moins que trop souvent, les attributions se fondent sur des analogies partielles et superficielles. Le cas de Giovanni Morelli est à cet égard exemplaire, voire caricatural [19], et plus récemment, et dans le domaine de la sculpture, on peut citer les travaux d’Armi [2, 3]. Ainsi, les excès de quelques-uns ont malheureusement contribué à jeter le discrédit sur cette méthode, alors que la critique aurait dû porter avant tout sur les conclusions, autrement dit sur l’usage d’une telle méthode.
En conséquence de quoi, le regard de l’historien de l’art s’est trop souvent éloigné de l’œuvre et n’en a restitué que les caractéristiques générales. Objectivement, il n’existe aucune raison de se priver de l’analyse systématique et comparative des détails, pour autant bien entendu qu’on ne la surévalue pas au détriment des informations fournies par les autres composantes de la peinture : la composition, les attitudes, l’adaptation aux contraintes architecturales, aux spécificités de la commande ou aux exigences de l’iconographie, la rapidité d’exécution, les matériaux disponibles, etc. L’apport du traitement d’images dans ce sens intervient pour la systématique et l’objectivité de la comparaison, les informations déduites de ces comparaisons peuvent ensuite être réintroduites dans l’analyse de l’œuvre et de son contexte.
Dans sa démarche, l’historien de l’art est influencé par sa culture visuelle, la documentation dont il dispose et, dans une certaine mesure, par la subjectivité de son regard et de son jugement. Cette subjectivité l’entraîne immanquablement à privilégier certaines caractéristiques formelles. On remarque par exemple que les mains retiennent généralement plus l’attention que les pieds. S’agissant des comparaisons, le chercheur encourt également le risque de se focaliser sur certaines régions ou certains courants artistiques et de négliger, faute de temps et de documentation, des œuvres plus éloignées ou méconnues. L’apport d’un système d’indexation par le contenu visuel et sémantique est de pouvoir réduire ces limites, de permettre de travailler sur l’œuvre suivant plusieurs critères métrologiques et de choisir plusieurs axes d’études parmi ces critères. Ces axes autorisent la confrontation de l’œuvre avec celles incluses dans la base de données. Si l’outil ne résout pas les problèmes de subjectivité du chercheur, il lui donne les moyens de mettre en balance tous les paramètres d’évaluation.
Deux exemples illustrent respectivement les limites suscitées par une approche trop superficielle et l’intérêt d’une observation plus poussée. Le premier concerne les peintures de Vicq (Indre). En dépit du caractère exceptionnel de leur facture, on s’est évertué à établir des liens généraux avec la peinture dite « de l’Ouest » d’une part, et des rapports plus étroits avec celles de Boí, en Catalogne (actuellement au MNAC). Les peintures de Vicq et de Boí partagent un sens du mouvement rarement égalé dans le monde roman, mais au-delà de cette analogie à laquelle s’ajoutent certaines conventions communes, les différences sont multiples et variées. La représentation des mains par exemple relève de procédés très différents : alors qu’à Vicq, les éminences thénar et hypothénar sont dessinées par deux traits séparés et situés dans le prolongement du pouce et de l’auriculaire, à Boí, ces deux traits sont très légers et ils se rejoignent au niveau du poignet. De plus, ces deux traits se prolongent à travers un trait plus marqué situé dans la continuité du contour de la main. On peut naturellement tirer des conclusions très diverses d’une telle observation, mais l’essentiel reste que si l’on veut comparer deux œuvres comme celles-ci, on ne peut en faire l’économie.
Le deuxième exemple concerne Poncé-sur-le-Loir (Sarthe). Davy a rapproché ces peintures de celles de Saint-Gilles-de-Montoire sur la base d’une importante série d’analogies formelles : décor, visages, mains, ciel… L’analogie la plus significative découle du graphisme très particulier appliqué à la bordure du vêtement du Christ dans ces deux églises, ce qui révèle l’emploi d’un canevas pour ainsi dire identique. L’auteur en a déduit que les deux ensembles avaient été exécutés par le même peintre. Une telle conclusion implique par la force des choses une part — même minime — de subjectivité et peut en conséquence être discutée car elle pose le problème de la définition des critères nécessaires et suffisants pour attribuer une œuvre à un même peintre. Une fois encore, ce ne sont pas les conclusions qui importent ici mais les moyens mis en œuvre pour les fonder. Or, les analogies observées sont suffisamment précises pour y voir un fait objectif.
Dans le cas de Poncé-sur-le-Loir, l’indexation par le contenu permettrait de multiplier les exemples d’occurrences du canevas observé ou, au contraire, de montrer qu’il n’apparaît jamais dans un corpus donné et attester par conséquent son caractère exceptionnel. Mais cette recherche ne prendrait tout son sens que dans le cadre d’une requête combinant l’ensemble des caractéristiques formelles de l’œuvre. Si le chercheur obtient des résultats aberrants, il pourra — en fonction d’un certain nombre de critères propres à la discipline — en déduire que l’œuvre étudiée ne peut être comparée à aucune autre, du moins sur la base des caractéristiques formelles prises en considération, ou au contraire que ces résultats doivent être écartés. À l’inverse, la recherche pourrait déboucher sur des suggestions plausibles que le chercheur n’aurait pas nécessairement envisagées.
Il ne s’agit donc en aucun cas de remplacer le regard et le jugement de l’historien de l’art par un outil informatique mais de fournir au chercheur des suggestions auxquelles il n’aurait pas songé. Si ce dernier vérifiait personnellement sous tous les angles toutes les comparaisons possibles, il pourrait sans doute obtenir de meilleurs résultats que le logiciel, mais il est probable par ailleurs que certaines combinaisons de caractéristiques formelles lui échappent. Les recherches menées avec de telles exigences sont de surcroît extrêmement longues, ce qui explique sans doute en partie leur rareté. L’intérêt de l’outil informatique réside donc également dans sa rapidité de traitement. Ainsi, de la même manière que l’on peut interroger aujourd’hui une base fondée sur l’indexation textuelle en lui demandant de signaler toutes les occurrences de tel thème isolé ou combiné avec tel autre thème dans telle aire géographique, on peut espérer que l’indexation par le contenu permettra de repérer des détails ressemblant le plus à ceux d’une œuvre étudiée sur la base de ses principaux paramètres formels.
Pour qu’un outil de ce type soit performant, il faut chercher à réduire les écueils auxquels sont confrontés les chercheurs, à savoir la limitation de la documentation et la subjectivité du regard. L’établissement d’un corpus d’images approchant de l’exhaustivité constitue précisément l’un des principaux objectifs de l’équipe « Peintures murales » du CESCM. Nous en sommes encore très loin aujourd’hui, mais le fonds est déjà considérable, ce qui a permis de commencer la recherche, et il continue de s’enrichir chaque année. Quant au risque de subjectivité, il peut être diminué en programmant le système informatique de telle sorte qu’il prenne en considération le plus grand nombre de caractéristiques formelles. Cela implique naturellement un travail de caractérisation de ces formes et, presque inévitablement, une part de subjectivité liée à la définition de ce qui doit être considéré comme caractéristique ou non du style, de la «manière» d’un peintre ou d’un atelier. D’autant qu’il n’existe aucune définition absolue permettant d’attribuer deux œuvres à un même artiste ou à un même atelier, et ce pour la bonne raison qu’il n’existe qu’un nombre extrêmement réduit de référents fiables. Il est souhaitable toutefois qu’à terme, le logiciel puisse être en mesure de prendre en considération le plus grand nombre de paramètres formels, y compris ceux qui n’auraient pas été définis préalablement.
Annexe 1 : Les partenaires du projet
Le CESCM
Depuis sa fondation en 1953, le CESCM, aujourd’hui FRE du CNRS et de l’université de Poitiers, a toujours eu pour vocation l’étude la civilisation médiévale dans sa richesse et sa très grande diversité, l’amenant à développer des recherches dans des domaines tels que l’histoire, l’histoire de l’art, la littérature, l’archéologie, l’épigraphie ou bien encore la philosophie et la musicologie. Au CESCM, les travaux d’histoire de l’art ont toujours privilégié l’étude de l’architecture, de la sculpture et de la peinture murale romanes, étant donné le choix de la région Poitou-Charentes fait par les autorités ministérielles des années cinquante pour localiser dans une aire géographique riche en patrimoine roman un centre de recherche international consacré à l’étude de la civilisation médiévale. Depuis peu cependant, l’ouverture est faite en direction des monuments gothiques sous l’impulsion de l’équipe « Le monument et son décor » dirigée par Claude Andrault-Schmitt. Internationalement reconnu pour les recherches menées dans le domaine de l’art roman en général et plus particulièrement des peintures murales des xie et xiie siècle, le CESCM a toujours su tirer parti de la richesse documentaire engrangée en son sein et principalement constituée d’un fonds photographique aujourd’hui riche de près de 150 000 clichés, tous supports confondus. Dans les années 1980-1990, la forte impulsion donnée par John Ottaway12 en faveur de la constitution structurée du fonds documentaire et de son exploitation scientifique a permis l’émergence de programmes de recherche forts axés sur la peinture murale romane ainsi que la réalisation de publications scientifiques de grande valeur. Ce dynamisme a été repris par d’autres chercheurs à la suite de John Ottaway, et notamment aujourd’hui par Marcello Angheben qui dirige les programmes de l’équipe « Peintures murales » du CESCM dont les travaux intègrent largement les réalisations documentaires effectuées dans le cadre de la photothèque. Parmi ces programmes, il en est un dont l’originalité et le caractère novateur n’ont pas échappé aux médiévistes comme aux spécialistes du traitement optique des images en tout genre. Il s’agit du programme de recherche que le CESCM et le laboratoire SIC ont développé en commun depuis trois ans dans le cadre du programme régional de l’Industrie de la Connaissance et des Images. Depuis peu, le CESCM sous la direction d’Éric Palazzo, a développé des compétences en matière de numérisation du patrimoine et de reconnaissance formelle d’images médiévales. Au sein de ce programme Aurélia Bolot gère le fonds iconographique et supervise le développement et les évolutions de la base de données.
Le laboratoire SIC
Le laboratoire SIC (Signal Image et Communications) est quant à lui une jeune équipe du CNRS issue de l’IRCOM-Limoges et qui a pris son statut de FRE en janvier 2004. Les activités du SIC s’inscrivent dans le secteur des Sciences et Technologies de l’Information et de la Communication (département STIC du CNRS), et plus précisément dans le domaine de l’Image et dans celui de la Transmission d’informations. Au sein du SIC, le thème ICONES (Images Couleur dyNamiques et statiquEs) coordonné par Christine Fernandez-Maloigne travaille notamment à la gestion de contenus multimedia sous l’animation de Noël Richard. Il s’agit pour les membres de l’équipe de définir des structures de données et des méthodologies permettant d’exploiter au mieux les informations contenues dans des bases de données numérisées. Il faut ainsi développer des outils performants et efficaces de recherche d’images — ou de régions d’images — d’intérêt, en exploitant la richesse sémantique contenue dans une image. Une attention toute particulière est notamment prêtée à la modélisation et à l’étude des couleurs au travers des formes, textures et mouvements des objets issus d’images numériques statiques ou dynamiques. Le SIC a désormais une réputation européenne qui l’amène à participer à des groupes de travail et des instances de normalisation internationales dans le domaine de l’image numérique couleur. L’ensemble des études se veut donc théorique mais ne peut être validé que par l’application des développements à des cas bien concrets qui vont de l’imagerie biomédicale au contrôle qualité industriel, en passant par le patrimoine artistique et culturel. Les méthodes développées placent alors l’utilisateur, le véritable expert, au cœur d’un système de gestion de la connaissance qui ne pourra jamais être autre qu’une aide au diagnostic.
Bibliographie
1 Angheben M., « Séraphins et chérubins dans les théophanies romanes de Catalogne et du nord des Pyrénées » dans Les fonts de la pintura romànica, Barcelone, 2004.
2 Armi C. E., Masons and sculptors in romanesque Burgundy. The new Aesthetic of Cluny III, London University Park, The Pennsylvania State University Press, 1983.
3 Armi C. E., The “headmaster” of Chartres and the origins of “gothic” sculpture, London University Park, The Pennsylvania State University Press, 1994.
4 Baschet J., Lieu sacré, lieu d’images, Les fresques de Bominaco (Abruzzes, 1263) : thèmes, parcours, fonctions, Paris, éd. La Découverte ; Rome, École française de Rome, 1991 (Images à l'appui, 5).
5 Bonne J.-C., « De l’ornement à l’ornementalité. La mosaïque absidiale de San Clemente de Rome », dans Le rôle de l’ornement dans la peinture murale du Moyen Âge. Actes du colloque international de Saint-Lizier du 1er au 5 Juin 1995, Poitiers, Centre d’Études Supérieures de Civilisation Médiévale, 1997 (Civilisation médiévale, 4), p. 103-108.
6 Bonne J.-C. « Repenser l’ornement, repenser l’art médiéval », dans Le rôle de l’ornement dans la peinture murale du Moyen Âge. Actes du colloque international de Saint-Lizier du 1er au 5 Juin 1995, Poitiers, Centre d’Études Supérieures de Civilisation Médiévale, 1997 (Civilisation médiévale, 4), p. 217-220.
7 Bonton P., Fernandez-Maloigne C. et Tremeau A. (ouvrage collectif), Image Numérique Couleur : de l’acquisition au traitement, Paris, Dunod, 2004.
8 CINES (Centre Informatique National de l’Enseignement Supérieur), Ministère de l’éducation nationale et ses partenaires : les bibliothèques détentrices des fonds et le CNRS-IRHT (Institut de Recherche et d’Histoire des Textes), Liber floridus [En ligne] http://liberfloridus.cines.fr/
9 Cocquerez J.-P. et Philipp S. Analyses d’images : filtrage et segmentation, Paris, Masson, 1995.
10 Groupe d’Anthropologie Historique de l’Occident Médiéval (GAHOM). Thésaurus des images médiévales pour la constitution de bases iconographiques, Paris, École des Hautes Études en Sciences Sociales (EHESS), 1993.
11 Davy C.. La peinture murale romane dans les Pays de la Loire. L’indicible et le ruban plissé, Laval, Société d’Archéologie et d’Histoire de la Mayenne, 1999.
12 Deng Y., Manjunath B.S. et Shin H., « Color image segmentation » dans IEEE Conference on Computer Vision and Pattern Recognition, vol. 2, p. 446-451, Fort Collins, CO, June 1999.
13 Dombre J., Systèmes de représentation multi-échelles pour l’indexation et la restauration d’archives médiévales couleur, thèse de doctorat, Université de Poitiers, décembre 2004.
14 Fayyad U.M., Piatetsky-Shapiro G. et Smyth P., « From data mining to knowledge discovery : an overview » dans Advances in knowledge discovery and data mining, Menlo Park, 1996, p. 1-36.
15 Gold S. et Rangarajan A., « A graduated assignment algorithm for graph matching », dans IEEE Transactions on Pattern Analysis and Machine Intelligence, 18/4, 1996, p. 377-388.
16 Larabi M.-C., Richard N. , Colot O. et Fernandez-Maloigne C., « Semi-automatic feedback using concurrence between mixture vectors for general databases » dans IST SPIE Internet Imaging III, vol. 4672, San Jose (USA), Janvier 2002., p. 81-90.
17 Liew A.W.C., Leung S.H. et Lau W.H., « Fuzzy image clustering incorporating spatial continuity » dans IEEE Proceedings on Vision Image Signal Processing, 147/2, avril 2000, p. 185-192.
18 Lim Y. W. et Lee S. U., « On the color image segmentation algorithm based on the thresholding and the fuzzy c-means techniques », Pattern Recognition, 23/9, 1990, p. 935-952.
19 Morelli G., De la peinture italienne. Les fondements de la théorie de l’attribution en peinture à propos de la collection des Galeries Borghèse et Doria-Pamphili, éd. Jaynie Anderson, Paris, Lagune, 1994.
20 Pailloncy J.G., Deruyver A. et Jolion J.M., « From pixels to predicates revisited in the graphs framework », 2nd IAPR Int. Workshop on Graph based representations, GbR99, mai 1999, p. 203-212.
21 Ranganath H. S. et Chipman L. J., « Fuzzy relaxation approach for inexact scene matching », Image and Vision Computing (IVC), 10/7, septembre 1992, p. 631-640.
22 Toubert H., Un art dirigé. Réforme grégorienne et Iconographie. Paris, Cerf, 1990, p. 93-192.