Application of Computerized Analyses in Dating Procedures for Medieval Charters
Michael Gervers
102063.2152@compuserve.com
Michael Margolin
Introduction
The primary objective of the DEEDS [1] research project is to develop a methodology for the analysis of the medieval « letter » or charter. The core of our approach is that unknown attributes of any given charter can be determined by comparison with a set of similar charters whose attributes are known. Once the methodology has been established, it can be used to make chronological evaluations, to identify related forgeries, to distinguish between and/or identify authorship ; and to undertake a wide range of historical research based upon analyses of content. The capacity to establish chronological boundaries for the individual medieval charter is particularly important in the case of England where, from the Norman Conquest in 1066 until the beginning of the reign of Richard I in 1189, only the occasional document issuing from the royal chancery bore a date. Over one million private charters survive from the twelfth and thirteenth centuries, but no more than eight percent of them can be accurately dated. In France, the custom of dating charters declined in a number of regions from the mid-tenth through the end of the eleventh century, especially in Normandy where the ducal chancery only reintroduced regular dating in 1204.
In general, any charter is an official legal document written or issued by a religious, lay or royal institution and therefore can be treated both as an independent entity and as the object of modelling and analyses. It is important to recognize that the English private charter of the twelfth and thirteenth centuries retains the form and purpose of its Norman pedigree : It dispenses with the traditional formality of the papal or imperial letter and with all that was not absolutely essential. Brevity and conciseness are its most recognisable characteristics. History reflects the individual circumstances which determined changes in the construction of legal texts and the constant adoption, formulation and adaptation of words and word expressions. While many such changes resulted from the obligation to respond to royal, episcopal and abbatial or prioral decree, others, such as the increasingly precise reference to topographical features, responded to the growing desire by administrators to record firm boundaries across the landscape. Underlying this whole process of change, however, is the phenomenon, common to all languages at all times, of obsolescence and word replacement. Put quite simply, changes in word usage and expression are the most immediate reflection of social change. Only when accurate dates have been assigned to a large corpus of charters from the period, however, will it be possible to determine when, and why, these changes took place
We believe (and preliminary analyses confirm) that chronological boundaries can be derived by studying the frequency distribution of terms and expressions extracted from a given charter over time. After taking into consideration any additional information that might be found in the text, such as the nature of the content, the structural organization of the text, topographical features, references to names of people and institutions, etc., final conclusions can be drawn by combining the results collected from the above analyses of each such component.
Process
The DEEDS Project’s Corpus presently includes about 7000 medieval Latin charters from twelfth- and thirteenth-century England derived from printed sources. All charters included in the Corpus are dated internally or by the editor of the collection using internal evidence. Obviously, the number of charters available for each chronological time span varies (fig. 1), as does the accuracy of the chronological evidence which varies from the exact day, month and year to a range of several years. In our research we resolve inconsistencies in the chronological attribution of charters by mapping the actual date of a charter to the corresponding computer-generated period, which might be as short as three years. This allows us to make the format of chronological attributes identical across the Corpus. The original date must fall completely or at least mainly within the time span of the given period. The newly-assigned period value allows the chronological attributes of each charter to be legitimately compared with the corresponding attributes of other charters in the Corpus. The set of periods can be viewed as a chronological grid that covers a given time span (in our case from the year 1050 to 1359).
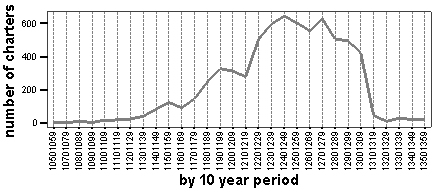
Figure 1 . Number of charters in the DEEDS Corpus over time
Grid steps can be constant (for example 3, 5, 10 or more years) or variable, to reflect the availability of charters in the given time span. While the use of a minimal-period grid step is obviously preferable from the point of view of accuracy, the use of larger steps, when necessary, allows us to use charters dated with longer date spans. The use of variable-period grid steps makes it possible to reduce the distortion of results caused by the unequal availability of securely-dated charters in the Corpus over time. When variable periods are being applied, all dates are initially mapped to the three-year period step and then some of the dates are remapped to wider periods to reduce fluctuations in the number of charters available for any given period over time (fig. 2, see also Appendix 1, fig. 24).
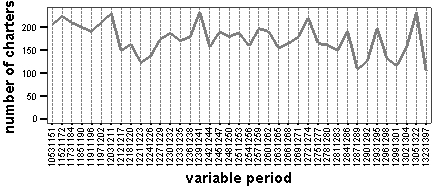
Figure 2 . Number of charters in the Corpus over time in a variable period grid
An average charter contains about 200 words (1 300 characters). Very short or very long ones are relatively uncommon (fig. 3).
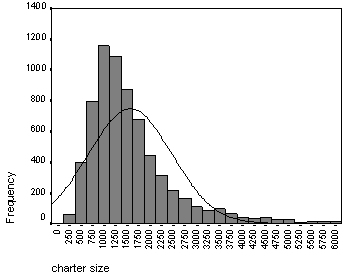
Figure 3 . Variations in the size of charters in the Corpus
Generally, the size of the charter is not specifically related to any time span or to the nature of its content (fig. 4).
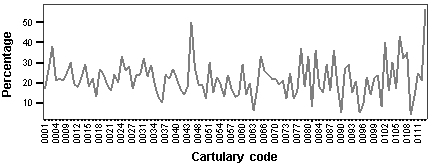
Figure 4 . Share of average-sized charters from collections represented in the Corpus
The Corpus is deployed on an Object-Relational Database Management System that provides fast and reliable access to the charters along with convenient maintenance facilities. The charter text is stored as a part of the textual structure called Source Document, which is a plain text document created using Extensible Markup Language (XML). A Source Document can easily be parsed by a computer or read by a person. A typical Source Document is a combination of the original unmodified text of the charter and complementary information derived from the charter itself, from the corresponding edition of the cartulary or collection of charters from which it is taken, or from external sources. Source Document is defined in terms of markup language as a « tree-like » hierarchy composed of the following elements : content, data, notes and markup. The original text of the charter is stored in the « content » element of Source Document. The information supplied under the « data » element includes attributes of the charter such as : content type (for example « Grant », « Quitclaim », « Confirmation »), type of chronological reference (anno Domini, regnal year, event, etc.), source of the text, issuer information, and topographical references. The « notes » element contains editorial information from external sources related to the given charter, divided by theme. The « markup » element holds sets of character-offset based maps created to facilitate detailed content searches. Each map stored in the « markup » element defines specific elements of the text.
The use of markup language for Source Document has made it possible to implement an extremely flexible repository of textual data and allows us to take advantage of modern textual search engines. The use of a database gives access to its indexing and exploratory facilities. The purpose of introducing Source Document is to encapsulate information and establish logical links between the text of the charter itself and complementary information related to the charter in sharable and portable form.
This approach allows us to produce on demand filtered versions of the Corpus, which are necessary when it has to be exposed to the external search engine or when some of the information stored in Source Document has to be shared over the Internet, or when some temporary changes need to be made to the charter text or to the format of its attributes.
Methodology
Our methodology is based on the premise that we can make accurate judgments about the unknown attributes of a charter by comparing it with other charters in the Corpus. Therefore, a match between the known attributes of a given charter with corresponding attributes in the group of charters allows us to assign values of other attributes back from the group to the given charter. Any feature of the charter that can be derived directly or indirectly from the text, reliably measured and then matched to the same features of other charters in the Corpus can be used as an attribute. Because our Corpus is composed of independent documents, the result produced by any matching of attributes can be nothing but a collection of attribute values (further referred to as a layer). An estimate of the attribute value associated with each layer can be obtained by using statistical techniques for measuring the central tendency of distribution along with an estimate of the expected margin of error. In subsequent stages of processing, results produced by any similar layer are collected in groups and each group is again considered as an independent layer. Eventually, a final estimate of the given attribute is computed by processing the last generated layer, which represents the result of multiple mergers of layers during the intermediate stages of processing.
In addition to its attributes, each charter can also be associated with a structural content model. This means that one or more content « maps » of the charter are created automatically or interactively and linked to the original text using the « markup » element of Source Document (see Appendix 1, Fig 23, 24). The text can then be modelled as a structure of specific elements of textual content. For example, the content « map » can describe a given text as a composition with three diplomatic parts : « Protocol », « Corpus » and « Eschatocol », or can identify wording in the disposition which states the essential nature of the act or describes the structure of the charter in terms of formulae (fig. 5).

Figure 5 . Markup of Bury St. Edmunds’ charter #140 [2]
Each of the markup colours in this example corresponds to a specific formula (fig. 6). A tree, as defined by Source Document, allows any element or group of elements to be matched independently to similar elements in the Corpus. The core of our methodology is an examination of charter vocabulary in the context of other features such as origin of the scribe, topographical references, people involved in the transaction, formulae used in the text, the structure of the text, and word placement within that structure.
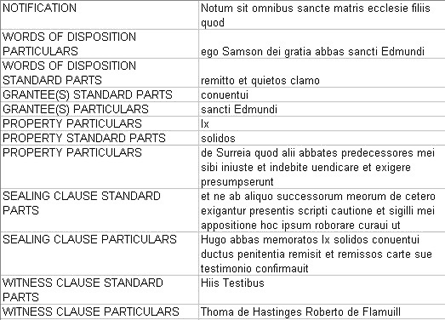
Figure 6 . Breakdown of the content of Bury St. Edmunds’ charter #140 into its diplomatic divisions
The examination of vocabulary involves extracting combinations of two or more adjacent words, so called word-patterns, in consecutive order from the text of the charter and then examining occurrences of each pattern in the Corpus. Lists of occurrences of each word-pattern are then analysed to generate estimates of the unknown attributes of the given charter.
The analysis of the frequencies of word-pattern occurrences is an important component of our methodology. We use Analyses of Frequency to estimate the unknown attributes of a charter by comparing them with charters in the Corpus. A system for identification of unknown attributes based on our methodology has been implemented as an Artificial Neural Network (fig. 7). Such architecture offers unparalleled power for discovering relationships between system components. The only potential disadvantage is that, without proper control, it could find relations that exist only by chance. The system relies heavily on a multiple-layer structure in which the higher layer concentrates information delivered by the lower level using multiple weighting factors. The human brain works similarly by grouping and weighting data, combining it into subgroups and finally producing a result or « decision ». There are multiple alternative direct-processing channels as well as a recursive feedback channel.
The feedback channel allows the system to be tuned when necessary by adjusting weighting factors. Initially this is done by processing attributed charters and optimizing the output by changing weighting factors. It is also possible to « retrain » the system to reflect changes after adding or removing charters from the Corpus. Results produced by all levels of processing are merged together using statistical techniques. Weighting factors are calculated according to the characteristics of each layer and are then verified and adjusted during system « training » cycles. Analyses of Frequency deliver the data, while other factors, like charter content type, issuer information and topographical references, define the boundaries of the analysis. For example, if the content type of a given charter can be identified, then that charter will be tested only against charters of similar type inside the Corpus. The same Analyses of Frequency may be repeated on results derived from more specific evaluations.
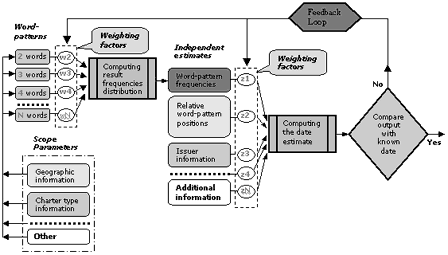
Figure 7 . Charter Evaluation Process
The computer program that implements this system has some additional features to address issues related to limitations of the charter text which we can neither completely avoid nor overcome. In the first place, since we are working entirely with published editions we are dependent upon the accuracy of their editors. If editors have inadvertently left out a word or words from the text, then they will be missing from our corpus as well. Some editors decided to replace what they considered to be similar word-patterns with « etc. » In reality those patterns might have incorporated subtle variations including temporal boundaries. Other editors leave supposedly « common » forms in abbreviation, while still others limit the reproduction of full Latin texts to charters issued before 1250 or even as early as 1100 ; the later material being translated or calendared in English regardless of whether or not it bears a date. Individual editorial decisions concerning capitalization and punctuation are not a problem, as we disregard them. Another potential shortcoming is that relatively few editions are based on original documents. The large majority of texts which have been transcribed are derived from cartulary copies, whose content may represent any number of earlier copyings. This is not to say that such copies are totally unreliable, but rather that they cannot be expected to be exact reproductions of the original. Medieval scribes, too, often replaced common phrases with « etc. », and left out what at the time may have been considered extraneous material, such as the witness lists. They may also have applied a degree of standardization in their preference for the use of letters c or t, i or j, and u or v. The normalized version of the Corpus has resolved most inconsistencies in a unified manner. By applying the same normalization to the charter being examined we create an alternative processing channel that can be used independently or in combination with others.
Analyses of Frequency begin by extracting sets of two or more consecutive words from the text of the given charter. The program starts from the first word and then moves down to the end of the text, extracting a fixed number of words in one-word steps (fig. 8, see also Appendix 1 fig. 25). The generation of sets ends when the word-pattern size reaches the size of the charter text or when no word-pattern in the given set occurs elsewhere in the Corpus.
et in omnibus modis
in omnibus modis et
omnibus modis et ingeniis
modis et ingeniis comodum
et ingeniis comodum suum
ingeniis comodum suum inde
comodum suum inde faciendum
Figure 8 . Example of word-patterns produced for Selby charter #224
When generation of the set has been completed the program starts searching for occurrences of each extracted word-pattern in the Corpus. The resulting distribution of occurrences is treated as an independent layer and is collected along with the properties of the individual word-pattern. There can be wide variation in the number and length of word-patterns in each set and in matches (hits) to patterns in the Corpus (Figs. 9 and 10 ; see also Appendix 1, Fig 25).
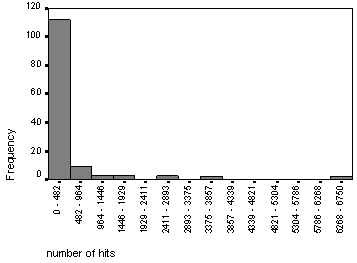
Figure 9 . Number of hits generated by all two-word patterns in Selby charter #224 [3]
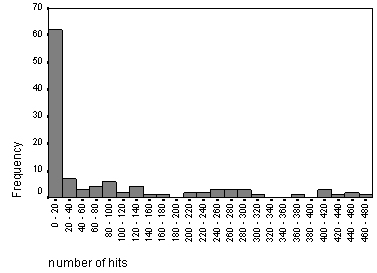
Figure 10 . Number of hits generated by two-word patterns in Selby charter #224, with the number of hits per pattern being
less than 480
As is seen on the chart, there are also a number of word-patterns that do not produce a statistically significant number of hits. Relations between the length of each word-pattern and the number of hits produced by it in the Corpus do not appear to be linear (figs. 11 and 12). This means that longer word-patterns do not necessarily produce fewer hits and vice versa.
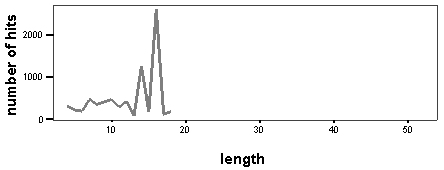
Figure 11 . Number of hits generated by patterns of two words, by length
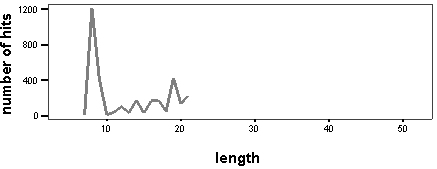
Figure 12 . Number of hits generated by patterns of four words, by length
Word-patterns extracted from a typical document will usually generate enough occurrences to apply standard statistical techniques for the evaluation of results (fig. 13).
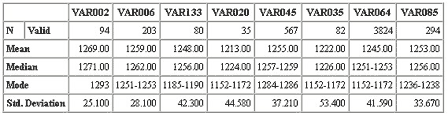
Figure 13 . Some word-pattern statistics
But the shape of distribution can vary considerably. For example, occurrences returned by word-pattern group #64 have Normal Distribution (fig. 14). But in the example of word-pattern group #008 (fig. 15) the distribution has quite a different shape. There are also a number of word-patterns in any set that produce very few occurrences. In that case the occurrences of all such word-patterns are collected together and then processed as a single distribution (fig. 16)
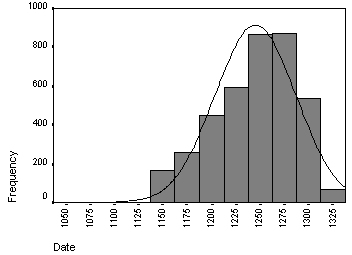
Figure 14 . Distribution of occurrences of word-pattern group #64 (2 words)
Figure 15 . Distribution of occurrences of word-pattern group #008 (5 words)
Figure 16 . Result distribution of word-patterns with small numbers of occurrences
After all word-patterns in the set have been processed, the system computes an estimate and expected margin of error for each pattern. In the following stages those word-pattern estimates are scaled, weighted and then grouped together into the word-pattern set-level layer and again the central tendency estimate and its margin of error are computed at that level. Further set-level estimates are scaled, weighted and then merged into the charter level layer for analysis. Computing an estimate and margin of error from the charter level layer concludes the Frequency Analyses for the given processing channel. Weighting factors used in the Frequency Analyses are always computed dynamically and depend on the individual properties of a given distribution member. The goal is to reduce distortions caused by natural variations in word-pattern sizes and properties between layers on all levels. Any future alternative processing channel will use the same mechanism of Frequency Analyses applied within different boundaries. Eventually, an estimate of unknown attributes is calculated by merging together estimates produced by all the processing channels.
Results
Currently we have implemented some of the main modules of the above system. We have a working prototype of the Frequency Analyses module, a scope modification module and a « first cut » of a dynamic weighting factor computation module. At this time we are concentrating on estimating the chronological attribute of the charter.
Our trial runs point to several of the most common types of output that might be produced by the system : conclusive, unclear and ambiguous. The thick line on the following charts shows a final estimate of the chronological attribute delivered by the initial processing channel, whose scope is not limited.
The conclusive result illustrated in Fig. 17 represents a case where there is a close match between the estimated chronological attribute generated by our system and the real date of the charter.
Figure 17. Lanercost charter #291[4] date : 1292
The unclear output seen in Fig. 18 illustrates a case where the shape of the distribution generated by the system is essentially flat. This means that any estimate of a central tendency will be accompanied by a large margin of error.
 Figure 18. Beauchamp charter #308 [5] date : 1261-62
Figure 18. Beauchamp charter #308 [5] date : 1261-62Fig. 19 displays a case of ambiguous output in which the system provides two or more clearly identifiable fluctuations in the shape of the graph.
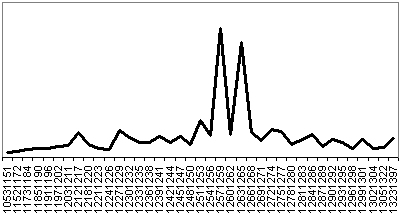
Figure 19. St. John’s Hospital, Oxford, charter #321, [6] date : 1265-66
Subsequent alternative channel processing usually confirms clear results and improves estimates produced by the initial processing channel. For example if spelling normalization and content-type scope reduction is applied the resultant output appears to be significantly better (Figs. 20, 21).
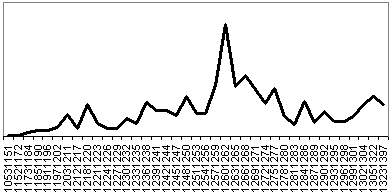
Figure 20. Beauchamp charter #308, dated 1261-62.
Spelling normalization and content-type scope reduction applied
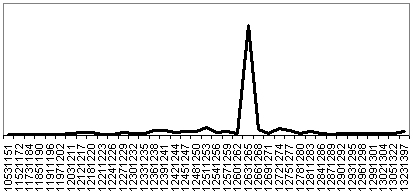
Figure 21. St. John’s Hospital, Oxford, charter #321, dated 1265-66.
Spelling normalization and content-type scope reduction applied
Future development
In the near future we intend to complete development of the dynamic weighting factor computation module and to test alternative statistical techniques for the calculation of intermediate and final estimates as well as expected estimate errors. Later, we plan to develop more alternative processing channels for the system and add a feedback channel to the existing system implementation. We are also considering making our system available over the Internet to the academic community.
[1]. Cet article fait suite à « The Deeds Project » de Michael Gervers dans le n° 41 du Médiéviste et l’ordinateur, p. 60-65. Site de DEEDS : http://www.utoronto.ca/deeds.
[2]. R. H. C. Davis (ed.), The Kalendar of Abbot Samson of Bury St. Edmunds and related documents, Camden third series, vol. 74, London, Royal Historical Society, 1954, n° 140.
[3]. J. T. Fowler (ed.), Coucher Book of Selby, vol. 1 of 2 vols., Yorkshire Archaeological and Topographical Association, Record Series, nos 10 & 13, 1891-1893, n° 224.
[4]. J. M. Todd (ed.), The Lanercost Cartulary, Surtees Society Publications, vol. 203 and Cumberland and Westmorland Antiquarian and Archaeological Society Record Series, vol. 11, Durham, 1997, n° 291.
[5]. Emma Mason (ed.), The Beauchamp Cartulary Charters, 1100-1268, Pipe Roll Society Publications, New Series, volume 43, for the years 1971-1973, London, 1980, n° 308.
[6]. H. E. Salter (ed.), A Cartulary of the Hospital of St. John the Baptist, vol. 1 of 3 volumes, Oxford, Oxford Historical Society, 1914-1916, no. 321.
ADDITIONAL BIBLIOGRAPHICAL REFERENCES
Marjorie Chibnall, « Dating the Charters of the Smaller Religious Houses in Suffolk in the Twelfth and Thirteenth Centuries », in M. Gervers, Dating Undated Medieval Charters, p. 51-59.
Georges Declercq, « A New Method for the Dating and Identification of Forgeries ? The DEEDS Methodology Applied to a Forged Charter of Count Robert I of Flanders for St. Peter’s Abbey, Ghent », in M. Gervers, Dating Undated Medieval Charters, p. 123-136.
Michael Gervers, « Changing forms of Hospitaller address in English private charters of the twelfth and thirteenth centuries », in The Crusades and the Military Orders : Expanding the Frontiers of Medieval Latin Christianity, ed. Zsolt Hunyadi and József Laszlovszky, Budapest, 2001, p. 395-405
—, « AThe Dating of Medieval English Private Charters of the Twelfth and Thirteenth Centuries », in A Distinct Voice : Medieval Studies in Honor of Leonard E. Boyle, O.P., ed. Jacqueline Brown & William P. Stoneman, Notre Dame (Indiana), 1997, p. 455-504.
— (ed.), Dating Undated Medieval Charters, Woodbridge, Suffolk & Rochester, NY : Boydell & Brewer, and Budapest : Collegium Budapest / Institute for Advanced Study, 2000.
—, « Identifying Irregularities and Establishing Chronology in Medieval Charters », in Keats-Rohan, Only Connect.
Penelope J. Gurney, and Lyman W. Gurney, « Authorship Attribution : A Computer-Based Approach to a Literary Crux in Late Roman Historiography », in TEXT Technology, Volume 10/1 (Winter 2001), p. 87-105.
—, « Enhanced content analysis of inflected languages through a system of computer-assisted lemmatization », Conference Abstracts of the 1994 Joint International Conference of the ALL and ACH, Paris, p. 93-94.
Zsolt Hunyadi, « The Identification of a Forgery : Regularities and Irregularities in the Formulae of the Charters issued by the Székesfehérvár convent of the Knights of St. John of Jerusalem (1243-1353) », in M. Gervers, Dating Undated Medieval Charters, p. 137-49.
Agnes Juhász-Ormsby, « Changing Legal Terminology in Dated Private Documents in England in the Twelfth and Thirteenth Centuries. A Case Study : Quitclaims », in Keats-Rohan, Only Connect.
Katherine S.B. Keats-Rohan (ed.), Only Connect : The Use of Computers in the Development of Prosopographical Methodology, Occasional Publication of the Unit for Prosopographical Research, Linacre College, Oxford, vol. 7, 2002.
Richard Sharpe, « Vocabulary, Word Formation and Lexicography », in F. A. C. Mantello & A. G. Rigg (eds.), Medieval Latin : An Introduction and Bibliographical Guide, Washington, D.C., 1996, p. 93-105 ; « Charters, Deeds and Diplomatics », ibid., p. 230-40.
Amanda Spencer, « Dating Charters Using Textual Evidence », in Keats-Rohan, Only Connect.
XML : W3C, REC-xml-1998-02-10 « Extensible Markup Language (XML) 1.0 », http://www.w3.org/TR/REC-xml