Note sur le traitement informatique des palimpsestes
Laurent Letellier
Laboratoire Calculateurs Embarqués et Image
CEA – Saclay
Dans le cadre du travail d’édition de textes grecs, la chaire d’histoire et civilisation du monde byzantin a demandé une assistance au Laboratoire calculateurs embarqués et images du commissariat à l’énergie atomique pour le traitement informatique de palimpsestes (manuscrits dont l’écriture originale a été gratée). Il s’agit d’essayer, à partir de clichés numériques, de faire ressortir le texte inférieur recouvert en grande partie par un texte supérieur.
Des essais de prise de vue réalisés avec un appareil photo numérique couleur ont été menés sur le manuscrit Parisinus graecus 1624 (xie / xive siècle), folio 30, en lumière visible, ultraviolette et infrarouge, et présentés sur un CD par le service reproduction de la Bibliothèque nationale de France.
Dans le but de faire ressortir le texte sous-jacent, les images en lumière visible sont les plus intéressantes. En effet, dans ces dernières et
surtout avec renforcement des contrastes (figure 1), le texte inférieur apparaît avec une teinte légèrement différente du texte supérieur.
Malheureusement les parties couvertes par le texte supérieur n’apparaissent pas visuellement et il semble difficile de pouvoir
les récupérer automatiquement.

Figure 1 : Éclairage en lumière visible – Renforcement des contrastes par filtre coloration verte
Les premiers essais de traitement ont été menés sur cette image. Une première idée était de passer du modèle de couleur RVB (Rouge, Vert, Bleu) dans lequel sont codées les images au modèle TLS (Teinte, Luminance, Saturation) pour travailler dans le domaine des teintes. Mais en fait, il s’avère plus facile de travailler directement dans l’image RVB. En effet, le texte inférieur possède une composante verte qui permet de le différentier facilement du texte supérieur pour les zones non couvertes.
Ainsi les traitement qui suivent ont tous été réalisés sur la composante
verte de l’image. L’extraction du texte inférieur se fait
par un simple seuillage entre les valeurs 100 et 200. Ces valeurs ont
été déduites de l’histogramme de l’image. Le résultat est
présenté figure 2.

Image 2 : Opération de seuillage sur la composante verte entre les valeurs 100 et 200.
On remarque sur la figure 2 que les bords du texte supérieur restent
présents malgré le traitement. Cela s’explique par le fait que la
couleur est moins marquée sur les bords de l’écriture. Ainsi elle
rejoint le niveau de celle du texte inférieur. Il faut donc envisager
un traitement supplémentaire pour éliminer ces contours parasites.
Pour cela, on a essayé de récupérer les bords du texte supérieur. On effectue cette opération en appliquant un filtre de type gradient sur la composante verte de la figure 1. Les contours du texte supérieur fournissent un gradient plus fort que l’on peut extraire par un seuillage adapté.

Image 3 : Contours du texte supérieur obtenus par gradient et seuillage
Ensuite, les zones communes entre les figures 2 et 3 sont éliminées de la figure 2. Ce traitement donne le résultat final présenté figures 4 et 5.

Image 4 : Résultat de la suppression des contours du texte supérieur
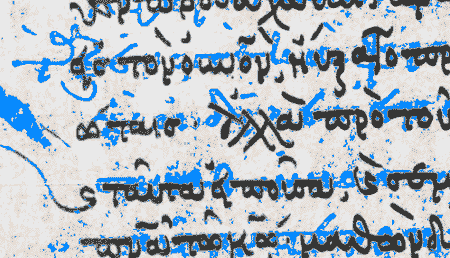
Image 5 : Résultat superposé au texte d’origine
Le résultat présenté ne concerne que les parties du texte inférieur non recouvertes par le texte supérieur. Il faut le considérer comme une illustration des possibilités du traitement automatique par analyse d’images. En effet, une étude plus poussée aboutirait sans aucun doute à un meilleur résultat.
Conclusion
Avec les clichés fournis par la Bibliothèque nationale, il nous semble impossible de faire ressortir le texte inférieur couvert par le texte supérieur. Par contre, les parties non couvertes sont accessibles à partir des images prises dans le visible. Le renforcement des contrastes est dans ce cas un élément intéressant pour accentuer la différence entre les textes et faciliter le traitement d’images.
La récupération d’une grande partie du texte recouvert ne peut se faire que par une étude approfondie sur les conditions de prises de vue (appareil de prise de vue et éclairage). Toute l’étendue du spectre lumineux doit être balayée afin d’essayer de trouver les conditions qui fassent ressortir au mieux le texte inférieur. Mais il est possible qu’il faille recourir à différentes conditions de prises de vue pour faire ressortir le texte inférieur d’un même manuscrit voire d’un même folio.